
How context engineering can affect your organization's decision quality
Why the decisions your AI agents make at scale are only as good as the context pipeline. The organizations that master it will win


Most enterprise agents are making decisions with incomplete information, stale data, and no memory of what happened five minutes ago. And the organization has no idea.
Decision quality is about to become the sharpest competitive edge in enterprise AI.
The agents reasoning over well-engineered context will simply outthink the ones that aren’t - faster, more accurately, at scale.
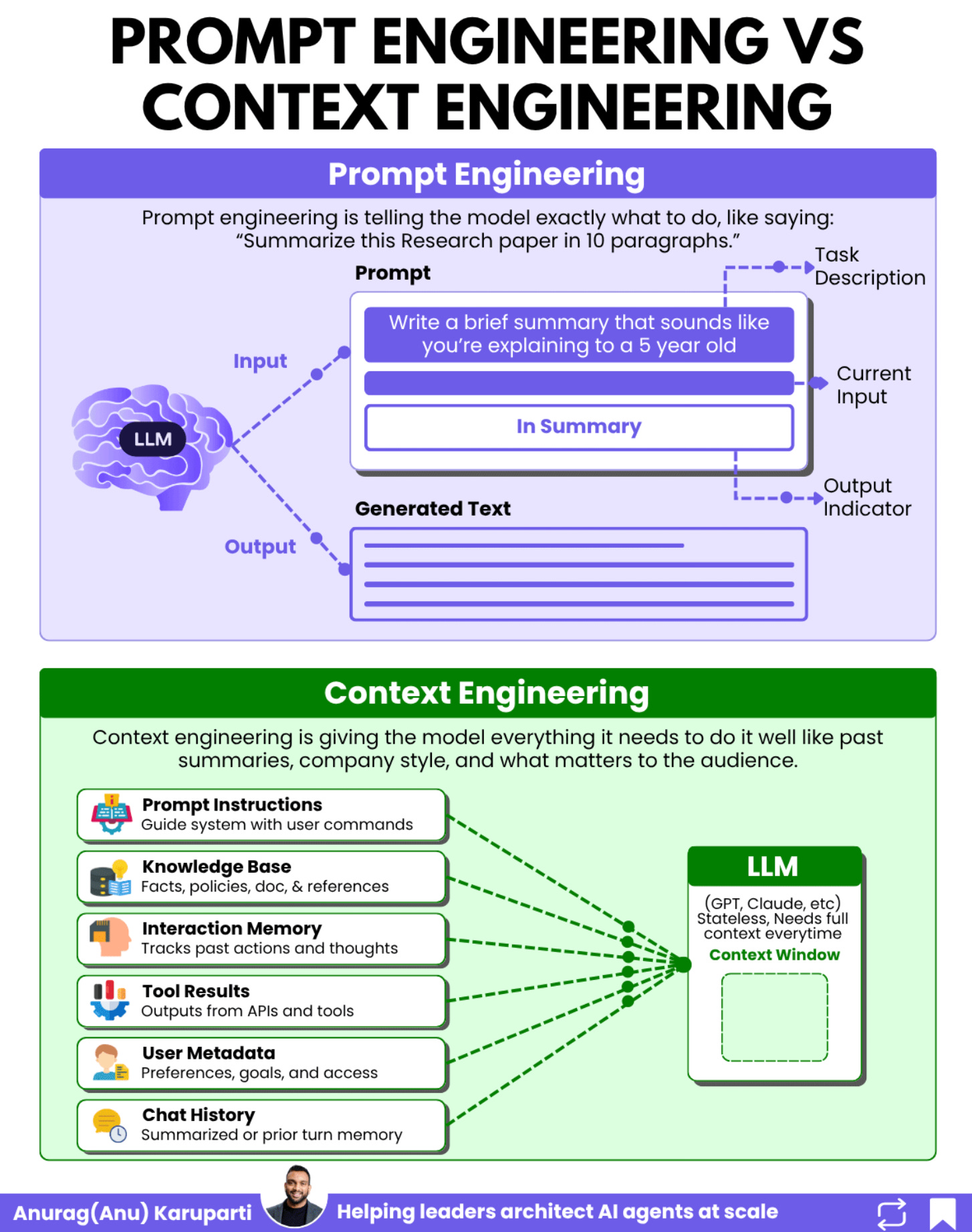
Prompt engineering is the art of asking the right question. Context engineering is the discipline of making sure your agent actually has everything it needs to answer it.
The quality of your agent’s decisions will separate winners from laggards in the enterprise AI race. Not the model you chose. Not your cloud provider. How well you engineered the context that agent reasons over.
You've seen it in every organization. Two equally smart people walk into the same meeting. One shows up cold, skims the agenda, and wings it. The other has read the brief, pulled last quarter's numbers, checked the client's recent support tickets, and already knows the CFO's concerns.
Same intelligence. Wildly different outcomes. That second person doesn't outthink the first. They out-context them. AI agents work exactly the same way.
Enterprises getting this right are deploying agents that catch fraud before it happens, route complex claims without human review, and generate code that is actually production grade. The ones getting it wrong are running expensive demos.
Prompt engineering got you to the prototype. Context engineering gets you to production.
The story
It was a Tuesday afternoon when Priya, the VP of Claims at a Fortune 100 insurance company, walked into an emergency leadership meeting.
Her team had spent $2.3 million on an AI agent system. Six months in development. And the week before, their claims agent had approved a $400,000 payout on a fraudulent claim.
The architecture looked solid on paper. A multi-agent system built on one of the best frontier models available. Well-designed agents. Clean orchestration. The hard work of mapping business logic to workflows had been done right.
But under the hood, the problem was obvious.
The claims agent was making decisions with incomplete context. It had no memory of previous interactions with that claimant. It couldn’t access the fraud detection rules that lived in a separate system.
The system prompt was a generic two-paragraph instruction that said “process insurance claims accurately.” The agent had the intelligence to do the job. It just didn’t have the information.
This is the story of 2026 enterprise AI. The models are smart enough. The frameworks are mature enough. The missing piece is context engineering.
And if you’ve been following my last four posts, you already know the building blocks.
Reliable agentic systems need engineering patterns that design around non-determinism.
Those systems need security architectures that treat every input as a potential attack vector.
Their ROI models need to account for the real cost of running agents safely at scale.
And the platform underneath needs to be a deeply integrated ecosystem, not a collection of disconnected tools.
Context engineering is the thread that connects all four. It’s the reason agents behave unreliably, the reason they’re vulnerable to prompt injection, the reason production costs blow past projections, and the reason fragmented platforms fail.
Fix the context, and you fix the root cause behind each of those problems.
If this mental model above gave you clarity on AI concepts,
I built a 74 visual AI library with animated guides that take you from agent basics to production grade architectures.
Agents. Agentic RAG.Multi agent orchestration.Enterprise governance. Production patterns.
Used by architects, engineers, and executives. 3 million plus impressions on Linkedin.
Built for fast clarity before meetings, interviews, and real world builds.
Get the full AI Visual Library here.
From Prompt Engineering to Context Engineering
Andrej Karpathy put it simply: context engineering is
“the delicate art and science of filling the context window with just the right information for the next step.”
Here’s the mental model that makes this click for enterprise architects:
The LLM is your CPU. It does the reasoning and processing.
The context window is your RAM. It’s the working memory the model uses for every decision.
Context engineering is your operating system. It decides what gets loaded into that working memory, when, and in what format.
Think about what happens when your laptop runs out of RAM. Applications slow down. They crash. They make errors. The CPU is perfectly capable, but it can’t perform without the right data in memory.
The same thing happens to your AI agents. When the context window is filled with the wrong information, or missing critical information, the most powerful model in the world will make bad decisions.
Priya’s claims agent didn’t fail because the model couldn’t reason about insurance fraud. It failed because nobody engineered the context to include the information needed for that reasoning.
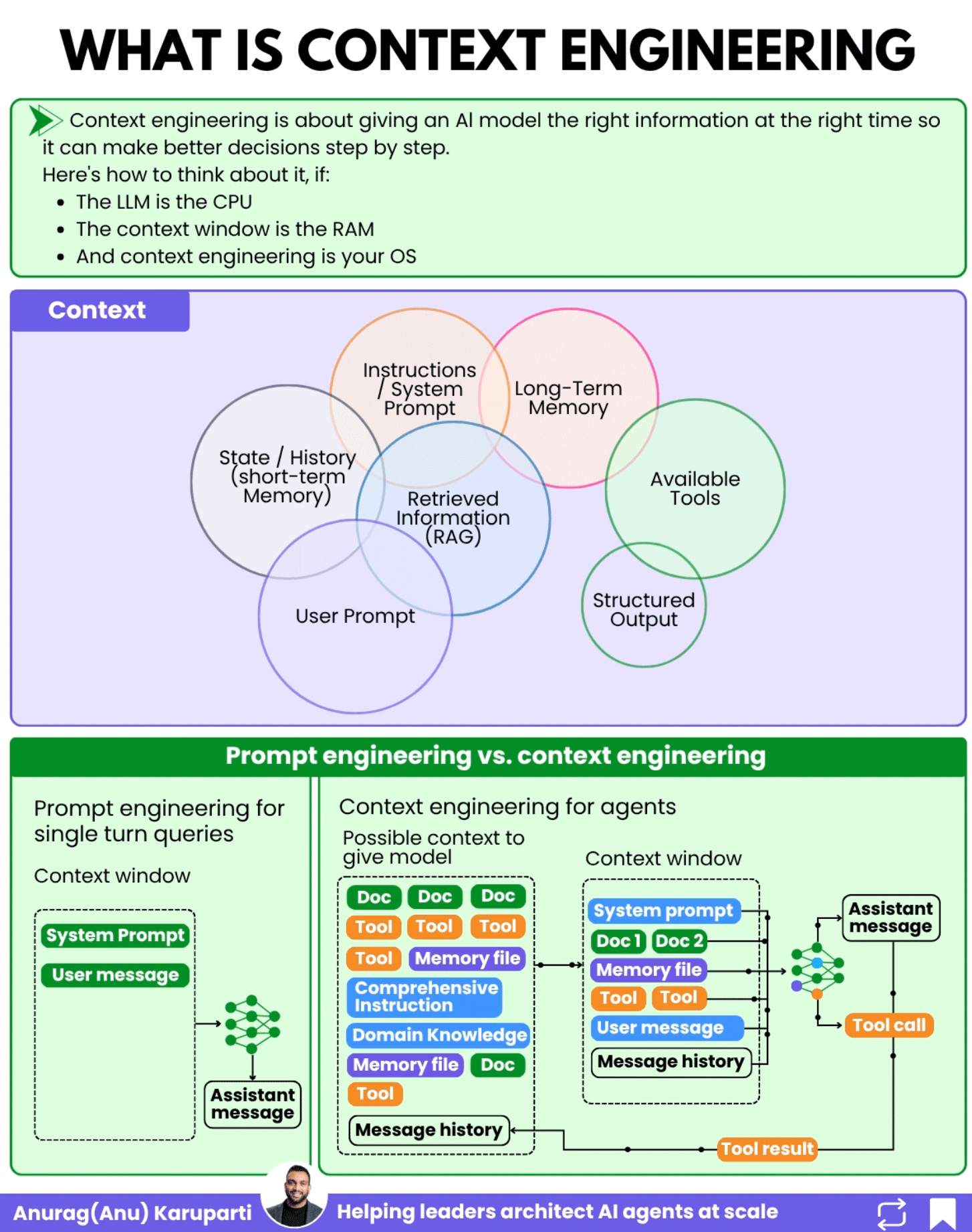
The Seven Components of Context for Enterprise Agents
When I work with Fortune 500 teams designing production agentic systems, I break context engineering into seven components. Each one serves a specific purpose, and getting any single one wrong can cause cascading failures.
1. Instructions / System Prompt
This is the foundation. Your system prompt is not a casual paragraph telling the agent to “be helpful.” In production, it’s a comprehensive specification that defines the agent’s role, boundaries, decision criteria, and escalation rules.
In my earlier newsletter on building reliable agentic systems, I talked about starting with contracts, not code. Your system prompt is the contract.
For Priya’s claims agent, the system prompt should have included: the agent’s specific role in the claims workflow, the exact criteria for auto-approval thresholds, mandatory fraud check requirements before any payout above $50K, and escalation rules for edge cases.
ROLE: You are a claims processing agent for auto insurance.
You handle property damage claims under $100K.
DECISION CRITERIA:
- Auto-approve claims under $10K with fraud score < 0.3
- Route claims $10K-$50K to senior adjuster queue
- MANDATORY: Run fraud_check tool before ANY payout above $50K
- NEVER approve claims where claimant has 3+ claims in 12 months
without human review
ESCALATION RULES:
- Fraud score > 0.7: Immediately route to SIU (Special Investigations)
- Missing documentation: Request specific documents, do not estimate
- Claimant dispute: Route to human adjuster with full context summary
CONSTRAINTS:
- Do not reference internal policy numbers in customer communications
- All monetary decisions must include reasoning chain in structured outputInstead, her team had: "You are a helpful insurance claims assistant. Process claims accurately and efficiently." That's a demo prompt, not a production specification.
2. Long-Term Memory
This is where most enterprise agent systems break down. Agents need persistent memory across sessions. Not just conversation history, but structured memory about entities, relationships, and decisions.
For a claims processing agent, long-term memory includes:
the claimant’s history, previous claims patterns, known fraud indicators associated with this account, and decisions made by other agents in related workflows.
For example: A telecom customer calls about a billing issue. Without long-term memory, the agent treats this as a first-time interaction. With proper long-term memory, the agent's context includes:
CUSTOMER ENTITY: Sarah Chen (ID: TC-449281)
- Account type: Enterprise (450 lines, $38K/month)
- Tenure: 7 years, high-value customer
- Churn risk: ELEVATED (scored 0.78 last quarter)
- Open issues: Billing dispute #BD-2024-1847 (unresolved, 12 days)
- Previous interactions:
- Jan 15: Called about 5G coverage gaps at Denver office (resolved)
- Jan 28: Escalated billing discrepancy for roaming charges (pending)
- Feb 3: Submitted written complaint via portal (auto-acknowledged)
- Agent notes: Customer expressed frustration about being "passed around."
Prefers direct resolution, do not transfer without context.
- Relationship: Reports to CTO James Park (also a decision-maker on renewal)Without this, the agent might offer Sarah a standard $50 credit when the real context demands executive-level retention intervention on a $456K annual account.
3. State / History (Short-Term Memory)
This is the conversation history and current session state. In multi-agent systems, this becomes critical because agents need to know what other agents have already done.
For example: An insurance claim triggers a three-agent workflow:
AGENT 1 (Intake): Receives claim, extracts details, classifies type
→ Passes state: { claim_type: "auto_collision", severity: "moderate",
documents_received: ["police_report", "photos"],
missing_docs: ["repair_estimate"], claimant_id: "TC-449281" }
AGENT 2 (Assessment): Runs fraud check, validates coverage, estimates payout
→ Receives Agent 1's state + adds: { fraud_score: 0.12,
coverage_verified: true, policy_limits: "$100K",
estimated_payout: "$23,400", assessment_confidence: 0.91 }
AGENT 3 (Resolution): Makes approval decision, generates communication
→ Receives Agent 1 + Agent 2 state + decides: auto-approve
(under $50K, fraud score < 0.3, coverage verified)Without state passing, Agent 3 would need to redo all of Agent 1 and Agent 2’s work, or worse, make a decision without their findings. This is the Amnesia Problem i discussed here.
Remember the Continuous Calibration, Continuous Deployment (CCCD) loop I described in the reliability post?
Each version of your agent (routing, copilot, resolution) generates different state management requirements.
A routing agent passes classification metadata. A copilot passes draft responses. A resolution agent passes full execution context.
If your state management doesn’t evolve with your agent’s autonomy level, context breaks.
4. Retrieved Information (RAG)
RAG is table stakes in 2026, but how you implement it for agentic systems matters enormously. The difference between a demo and a production system often comes down to retrieval quality.
For example: A financial advisor agent needs to answer: “Can this client invest in private equity funds?” A bad RAG implementation retrieves five loosely related compliance documents and dumps 8,000 tokens of legal text into context. The agent hallucinates a policy interpretation.
A good implementation:
Query: "client eligibility private equity investment"
Retrieved (hybrid search, 3 results, access-controlled):
1. [Relevance: 0.94] Accredited Investor Policy v3.2 (Section 4.1)
"Clients with net worth > $1M excluding primary residence OR annual
income > $200K for past 2 years qualify as accredited investors..."
2. [Relevance: 0.91] Private Equity Fund Suitability Requirements
"Minimum investment: $250K. Lock-up period: 7 years. Client must
acknowledge illiquidity risk in writing before allocation..."
3. [Relevance: 0.87] Client Risk Profile: James Park (ID: FIN-82941)
"Risk tolerance: Aggressive. Net worth: $4.2M. Current PE allocation:
12%. Maximum PE allocation per IPS: 20%..."
→ Total context added: 1,200 tokens (not 8,000)
→ Agent can now make a grounded, auditable decisionThat last point connects directly to something I covered in the AI security post. Every retrieved document is a potential injection vector.
If your RAG pipeline pulls in a poisoned document containing hidden instructions, your agent will process those instructions as legitimate context.
This is the Cross-Domain Prompt Injection (XPIA) attack I broke down in detail in my security post.
Your retrieval pipeline isn’t just a knowledge source. It’s an attack surface.
5. Prompt
This is the actual request or input that kicks off the agent’s work. In enterprise systems, the “user” could be another agent, a scheduled trigger, or an event from an external system, not a human typing a message.
6. Available Tools
Tools are the hands and feet of your agent. They define what the agent CAN do, not just what it KNOWS.
In the context window, tool definitions tell the model what actions are possible, what parameters are needed, and what the expected outputs look like.
This connects directly to MCP (Model Context Protocol) and it makes tools discoverable and invokable consistently across services. When your agent knows it has access to a fraud detection API, a claims database, and a document verification service, it can plan its work accordingly.
7. Structured Output
The last piece. Defining the expected output format ensures the agent’s response can be consumed by downstream systems, other agents, or human reviewers. In enterprise workflows, structured outputs (JSON schemas, typed responses) are not optional.
For example: When a claims agent completes its assessment, it needs to produce output that downstream systems can consume without parsing natural language:
❌ UNSTRUCTURED OUTPUT:
"I've reviewed the claim and it looks good. The amount seems reasonable
and I didn't find any fraud indicators. I recommend approving it for
around $23,000."
→ Downstream systems can't parse "looks good" or "around $23,000"
→ No audit trail for the decision rationale
→ Human reviewer has to read and interpret
✅ STRUCTURED OUTPUT:
{
"decision": "APPROVED",
"claim_id": "CL-2024-9847",
"approved_amount": 23400.00,
"currency": "USD",
"confidence_score": 0.91,
"fraud_risk_score": 0.12,
"reasoning": [
"Coverage verified: comprehensive auto policy active",
"Fraud score 0.12 below threshold 0.3",
"Amount $23,400 within auto-approval limit $50,000",
"No prior claims in 12-month window"
],
"required_actions": [
{ "type": "payment", "amount": 23400.00, "recipient": "claimant" },
{ "type": "notification", "channel": "email", "template": "claim_approved" }
],
"escalation_flags": [],
"audit_metadata": {
"agent_id": "claims-assessor-v3.2",
"model": "gpt-4o-2024-11-20",
"context_tokens_used": 4847,
"tools_called": ["fraud_check", "coverage_lookup", "claims_history"]
}
}The structured output feeds directly into the payment system, notification service, and audit log without any human interpretation. The reasoning array creates an auditable decision trail. The audit metadata tells you exactly which model and tools were used, critical for compliance.
This connects to the reliability pattern of constraining outputs that I covered in the reliability post. Low temperature, structured response schemas, and strict validation gates. You’re not looking for identical text every time. You’re designing for deterministic outcomes from non-deterministic components.
Why this matters more for your AI agents
Prompt engineering was designed for single-turn interactions. You type a question, you get an answer. Context engineering is fundamentally different because agentic systems are fundamentally different.
Here is the core difference: In prompt engineering, a human crafts a static prompt. In context engineering for agents, a system dynamically assembles context from multiple sources at runtime, often across multiple steps, with each step building on the previous one.
Consider a typical enterprise agentic workflow:
Step 1: A customer files a claim. The orchestrator agent receives the trigger and loads the system prompt, the customer’s history from long-term memory, the claim document via RAG, and the available tools (fraud check API, payout system, escalation queue).
Step 2: The claims agent processes the request. It calls the fraud detection tool, receives a risk score, and adds this to its working context. It retrieves similar past claims via RAG. It checks policy limits from the knowledge base.
Step 3: Based on the accumulated context, the agent either approves the claim (structured output to payout system), flags it for human review (handoff with full context summary), or denies it (structured output with reasoning).
At every step, the quality of the agent’s decision depends entirely on what’s in the context window.
Miss the fraud score? Bad decision.
Lose the conversation state between steps? Repeated work or contradictory actions.
Wrong retrieval results? Hallucinated policy interpretation.
Why context failures map to every problem I’ve written about
If you have read the last four posts, the pattern is clear.
Every production failure traces back to context engineering.
1. Reliability failures are context failures
Non deterministic AI forces you to engineer guardrails.You lock inputs. You constrain outputs. You separate reasoning from execution. Each of these is a context decision.
Lock inputs. You version prompts, system messages, and retrieval sources.
Constrain outputs. You define strict schemas and structured responses inside the context window.
You keep tool definitions clean and deterministic in context.
If context is loose, behavior becomes unstable. Reliability degrades first.
2. Security breaches are context breaches
The fake invoice attack worked because untrusted content entered the context window unsanitized.
The lethal trifecta:
Access to private data
Exposure to untrusted tokens
An exfiltration path
This is not just a model issue. It is a context pipeline issue.
If your retrieval layer injects malicious instructions into context, the model will follow them. If you sanitize and isolate retrieved content before assembly, you remove the primary attack surface.
Security begins with disciplined context assembly.
3. ROI overruns are context cost overruns
The projected 10x ROI that dropped to 2x was not a math error.
It was a context cost miss.
Hidden cost drivers:
Tool execution
Retrieval infrastructure
Evaluation pipelines
Monitoring systems
Bloated context increases token usage per call. Poor retrieval wastes tokens on irrelevant documents. Missing memory forces repeated reasoning.
4. Ecosystem fragmentation is context fragmentation
Six pilots. Four vendors. No shared identity. No shared memory.
Each system had:
A separate identity model
Separate data contracts
Separate retrieval patterns
A separate memory store
No agent could assemble unified organizational context. The problem was not tooling alone. It was broken context flow.
When identity, governance, and data contracts are unified, context can move across the stack. When they are fragmented, agents remain shallow and siloed.
Across reliability, security, ROI, and ecosystem strategy, the root cause is the same. Context is the control plane of agentic systems. Engineer it deliberately or pay for it later.
Closing Point
The models will keep getting smarter. The frameworks will keep getting better. But the quality of your AI agent’s decisions will always be bounded by the quality of context it receives.
Context engineering is the discipline that separates the teams shipping production agents from the teams stuck in pilot purgatory.
It’s the reason some multi-agent systems deliver real ROI while others approve $400,000 fraudulent claims.
If you’ve been following this newsletter, you now have the full picture:
Build reliability by designing around non-determinism with locked inputs, constrained outputs, and continuous calibration
Secure your agents by treating every context source as a potential attack vector and red teaming continuously
Prove ROI by accounting for the full cost of context engineering in your business case
Build on the right platform so context can flow across a unified, governed ecosystem
Context engineering is the thread that ties all of it together. Master it, and you’re not writing clever prompts. You’re architecting systems that get the right information to the right agent at the right time.
That’s the whole game.
Here are some more interesting reads on context engineering
https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
https://www.philschmid.de/context-engineering
Context seems to be a stretch for traditionally educated engineers. Context setting is critical in the AI-verse, so interestingly enough, Humanities based designers may have an edge.