
How to build reliable agentic systems from non-deterministic AI
The engineering patterns that make probabilistic AI more production ready

Last week on Lenny’s podcast, I heard from AI experts Aish and Kiriti on how building agentic applications differs from traditional software. It was reassuring to hear them describe the same patterns I see in the field and similar design approaches I have been recommending to my customers.
Certain characteristics of modern AI systems demand new approaches to solution architecture and development.
The core challenge: non-determinism

Traditional software is deterministic. Same input, same output, every time. Agentic applications break this model. They’re powered by Gen AI models that are non-deterministic by design. This isn’t a bug. It’s the feature that makes them intelligent.
But here’s the problem: businesses need reliability. Customers need consistency. Regulators demand auditability.
So how do you build reliable systems from unreliable components?
Design principles for agentic systems
They highlighted key patterns that diverge from traditional software development:
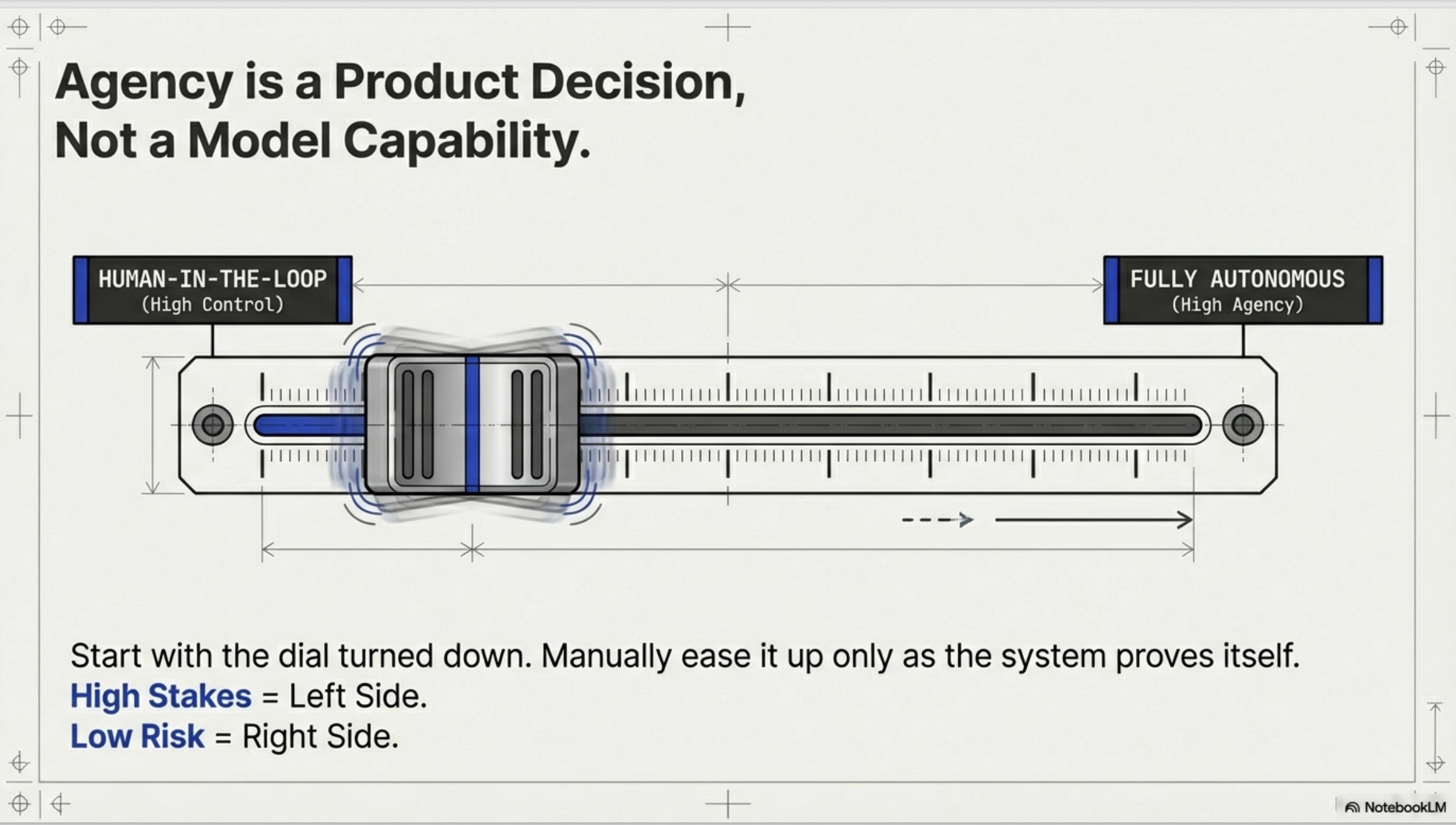
1. Agency vs Control - Pick your trade-off
Decide upfront how much autonomy you’re willing to give the system. For high-stakes, high-economic-impact use cases, humans stay in the loop. For low-risk workflows, let the agent run.
For most use cases start with high human control and low agency (less agency for agents). Continusly Calibrate, improve your solution until you are confortable trading off control with agency.
This isn’t just a technical decision. it’s a business decision.
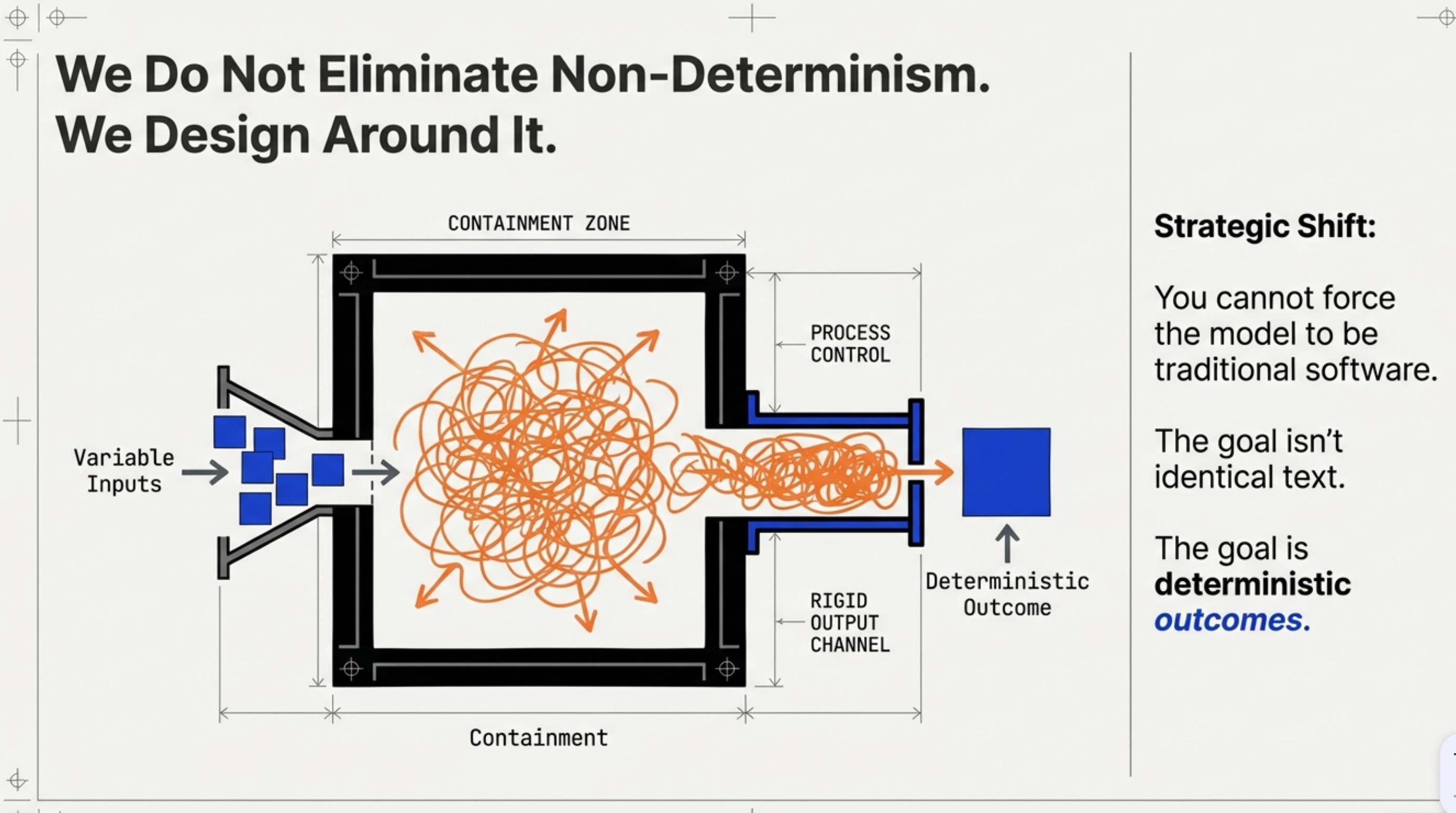
2. You don’t eliminate non-determinism. You design around it.
Here’s what works in production:
Lock your inputs. Version everything: prompts, tools, schemas, system instructions. Treat them like code.
Constrain your outputs. Low temperature, structured responses (JSON schemas), strict validation gates.
Separate reasoning from execution. Let the model propose a plan. Validate the plan. Execute actions through deterministic functions via tool calls. Keep reasoning and execution strictly separated.
Add guards and fallbacks. When confidence scores drop or policy checks fail, route to a known safe path.
The goal isn’t identical text every time. It’s deterministic outcomes.
3. Evals, Tracing, and the Signals That Matter
As agents start taking actions, your monitoring strategy changes:
Build evals in collaboration with SMEs, not just engineers. They know what “good” looks like for business outcomes.
For high-throughput systems, you’ll drown in trace data. Identify which traces matter. Identify edge cases and failures.
Track both explicit feedback (thumbs up/down) and implicit signals (regenerations, abandonment, escalations to humans).
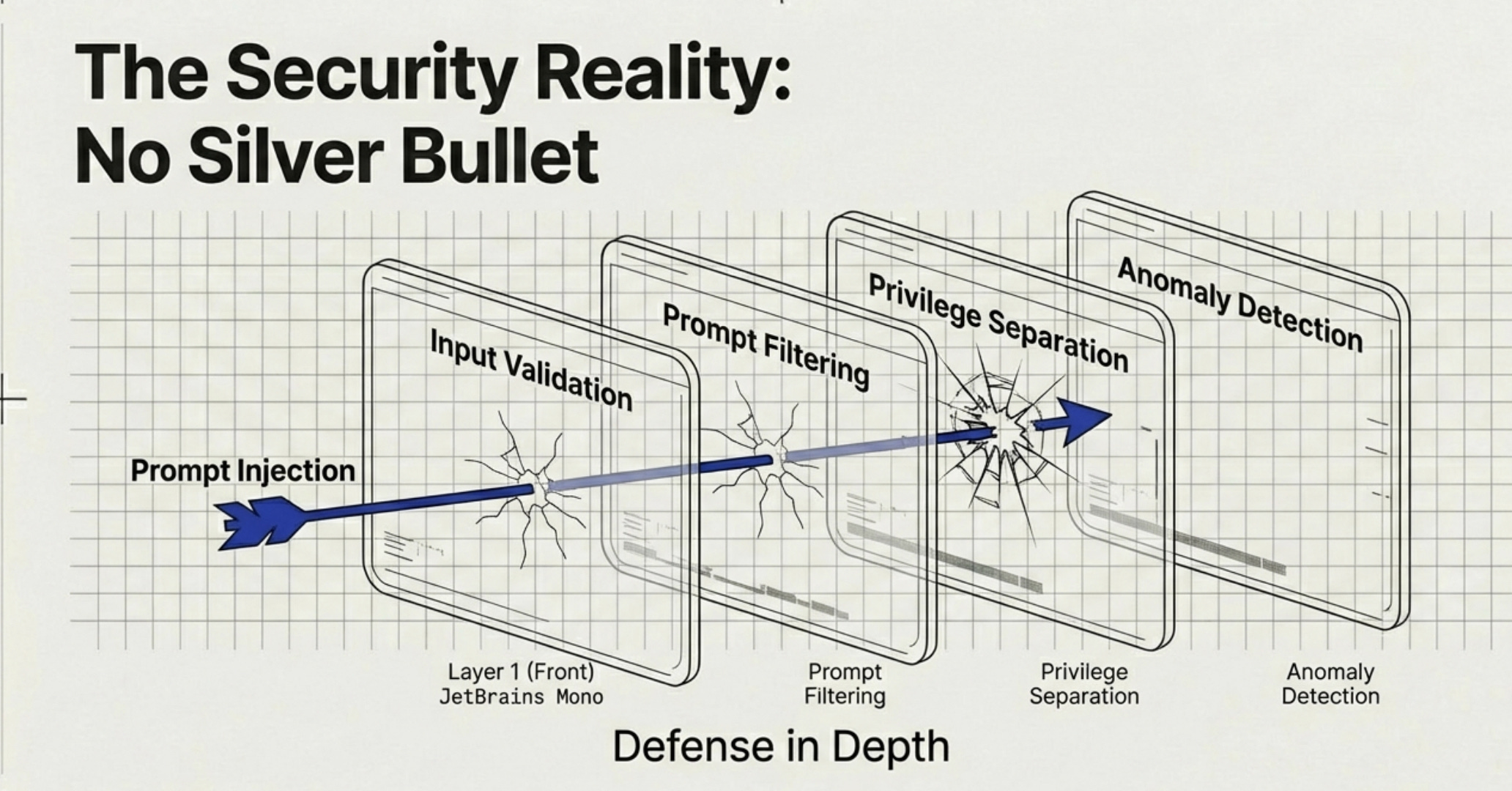
4. The security problem nobody’s solved
Prompt injection is real. Users can phrase questions in countless ways, potentially hijacking your system. There’s no silver bullet yet, but layered defenses help: input validation, output filtering, privilege separation, and monitoring for anomalies.
Use agents like Red Teaming Agent from Microsoft, to proactively assess for security risks.
The leadership gap
Here’s where most organizations fail and it’s not technical.
Leaders must go hands-on. This technology moves too fast to delegate understanding. You can’t make good decisions about agentic AI using mental models from traditional software development.
I liked the example Aish shared about a CEO who blocks two to three hours every morning just to experiment with these tools. That hands on time leads to better strategic decisions, stronger intuition, and less disconnect with engineering teams.
Create a culture of empowerment. SMEs and domain experts need to feel ownership over improving the AI system, not threatened by it. Without their collaboration, your evals will be shallow and your system won’t reflect real-world needs.
Process: Continuous Calibration Continuous Deployment
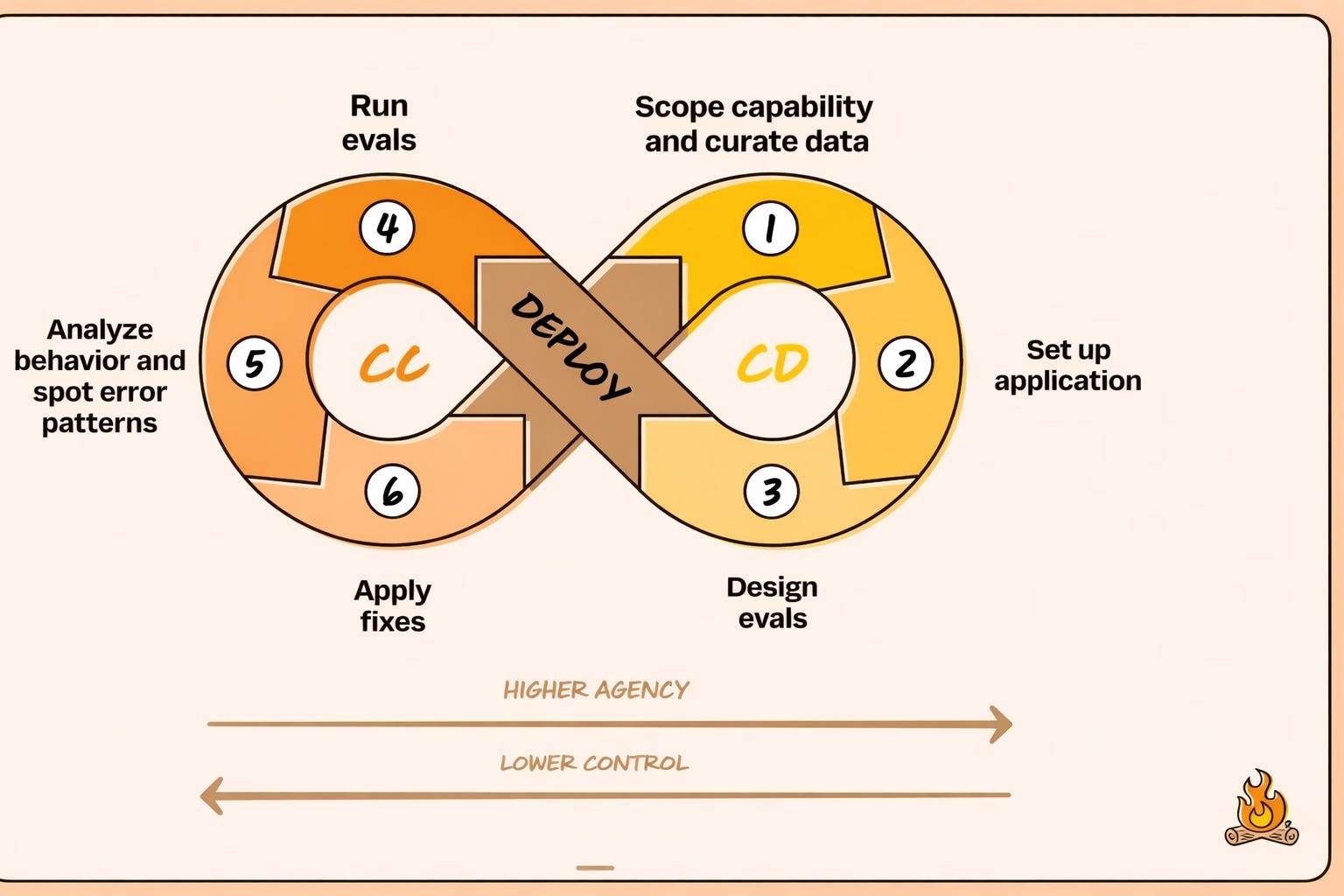
This is where the conversation really clicked for me.
Instead of chasing fully autonomous agents from day one, Aishwarya and Kiriti described a simpler, safer loop: Continuous Calibration, Continuous Development.
You start by scoping a narrow capability, curating a small but representative dataset, and defining clear evaluation metrics. You deploy first with high control and low agency. Then you watch how real users interact with the system.
What matters is not just whether the agent passes known evals, but what surprises show up in production. New behaviors. New failure modes. New data distributions you never anticipated.
That feedback drives calibration. You analyze behavior, spot error patterns, fix what broke, and evolve your evals. Only when surprises drop and behavior stabilizes do you increase agent autonomy.
This loop does two things at once. It protects user trust by avoiding unsafe autonomy early. And it creates a learning flywheel where each version teaches you exactly what the next version needs.
Agentic systems do not become reliable by eliminating non determinism. They become reliable by continuously calibrating behavior and earning autonomy over time.
Agency grows in stages, not all at once
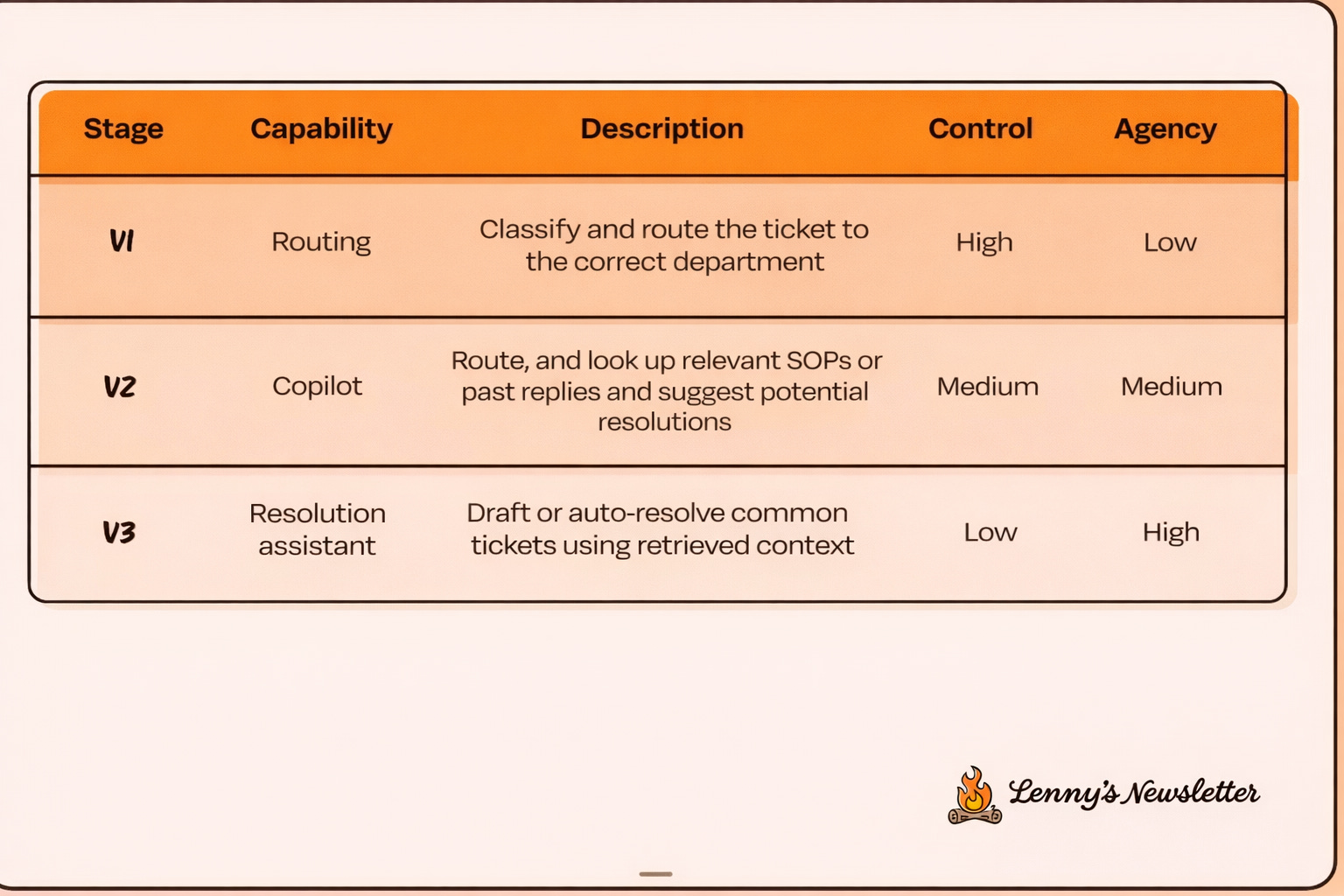
The above slide makes the agency trade off concrete.
You do not jump straight to autonomous agents. You earn autonomy.
Version 1 is routing. The system only classifies and routes tickets. Control stays high. Humans can easily correct mistakes. This stage exposes messy taxonomies, bad labels, and hidden business rules.
Version 2 is copilot mode. The system retrieves SOPs and past replies and drafts suggestions. Humans review and edit. Control and agency are balanced. This stage reveals what context actually matters and where retrieval breaks down.
Version 3 is a resolution assistant. The system resolves narrowly scoped tickets end to end. Agency is high. Control is lower. By the time you reach this stage, trust has already been earned through prior iterations.
This framing makes one thing clear. Agency is a product decision. Not a model capability decision.
Every version feeds the next loop
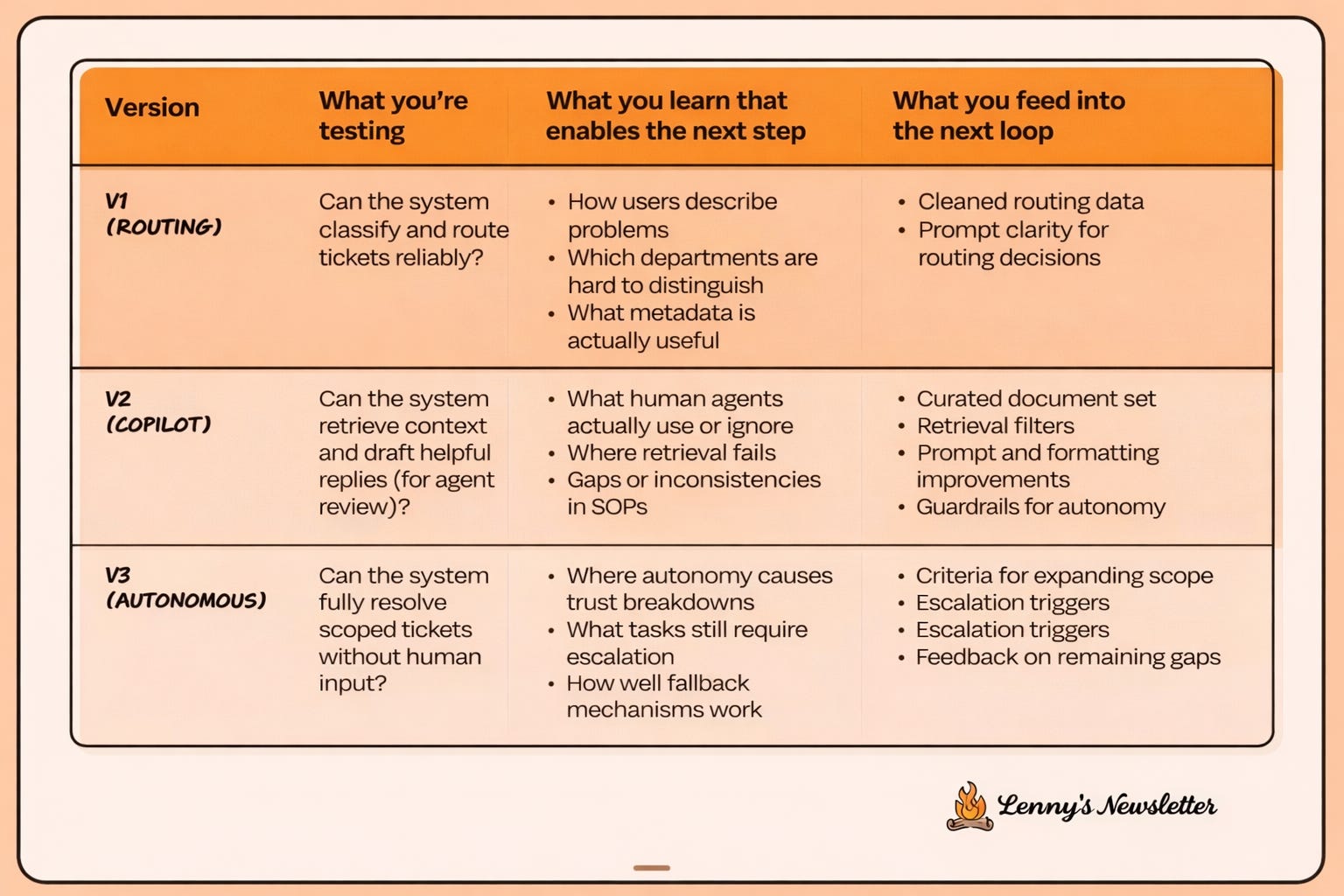
The above slide explains why this works in practice.
Each version is not just delivering value. It is teaching you something specific.
Routing teaches how users describe problems, which categories are ambiguous, and what metadata matters. That feeds cleaner data and better prompts.
Copilot mode teaches what humans accept or ignore, where Standard Operating procedures (SOPs) are inconsistent, and how retrieval fails. That feeds document curation, retrieval filters, formatting, and guardrails.
Autonomous resolution teaches where trust breaks, what still needs escalation, and how well fallbacks work. That feeds scope expansion criteria and escalation rules.
This is the hidden advantage of CCCD. You are not guessing what to build next. The system tells you.
Reliable agentic systems are not designed upfront. They are discovered through disciplined calibration.
In Summary
Building reliable agentic systems isn’t about making AI deterministic. It’s about designing architectures that produce consistent outcomes despite the non-determinism underneath.
If this helped you think differently about AI architecture, feel free to share it with someone building or deploying AI systems right now.
I also host a subscriber chat where I share practical architecture frameworks, templates, and resources to help you build production-ready agentic AI systems.
