
How to build a strong enterprise AI moat with context engineering and data estate
Strong models on weak data make weak enterprise agentic systems. Here's how to build a 3-layer framework to catch up before the window closes.


Context engineering is about to become your organization’s strategic advantage.
In 24 months, it will separate the AI winners from the dead. Model intelligence is commoditizing fast. Every competitor has access to the same frontier models you do. What they don’t have is your data, your governance, or your retrieval architecture. That combination is unique to you, and it directly shapes the quality of every decision your agents make for your organization.
I've been beating this drum for a while (previous edition here). This week I want to focus on the layer underneath context engineering, the one that decides whether your agents are smart or confidently wrong: your data architecture.
Most AI agent failures aren’t model problems. They’re data architecture problems.
You can run GPT-5.4 on garbage data and get confident, hallucinations, authoritative-sounding garbage back. I’ve seen it.
Your competitors are building on the same foundation models you are. The model is not the moat and never was. Your data layer is. Because that is what feeds into the context window of the models.
Organizations that figure out how to give agents the right data, at the right time, in the right shape are about to pull so far ahead that companies still arguing over which LLM to use won’t even be in the same conversation.
This week’s edition is about that gap.
The team with perfect models and broken agents
Last year, I was advising a large fortune 500 logistics company. Call the lead architect Marcus. Marcus’s team had done everything right on the model side: latest frontier models, fine-tuned retrieval, sophisticated prompt templates.
Six months into production, their AI agent was still giving customers wrong shipping estimates, hallucinating carrier policies, and occasionally pulling refund rules that had been deprecated two quarters ago.
The post-mortems kept pointing to the model. The team kept tweaking prompts. Nothing moved.
When I sat down with their data team, I found the real problem in about 20 minutes. Carrier rate tables lived in three different systems with no sync schedule.
Return policies were documented in a SharePoint site no one governed. Inventory data flowed through a pipeline with a 48-hour lag.
The agent wasn’t broken. It was operating on a broken data estate.
Marcus’s team had spent six months optimizing the wrong layer.

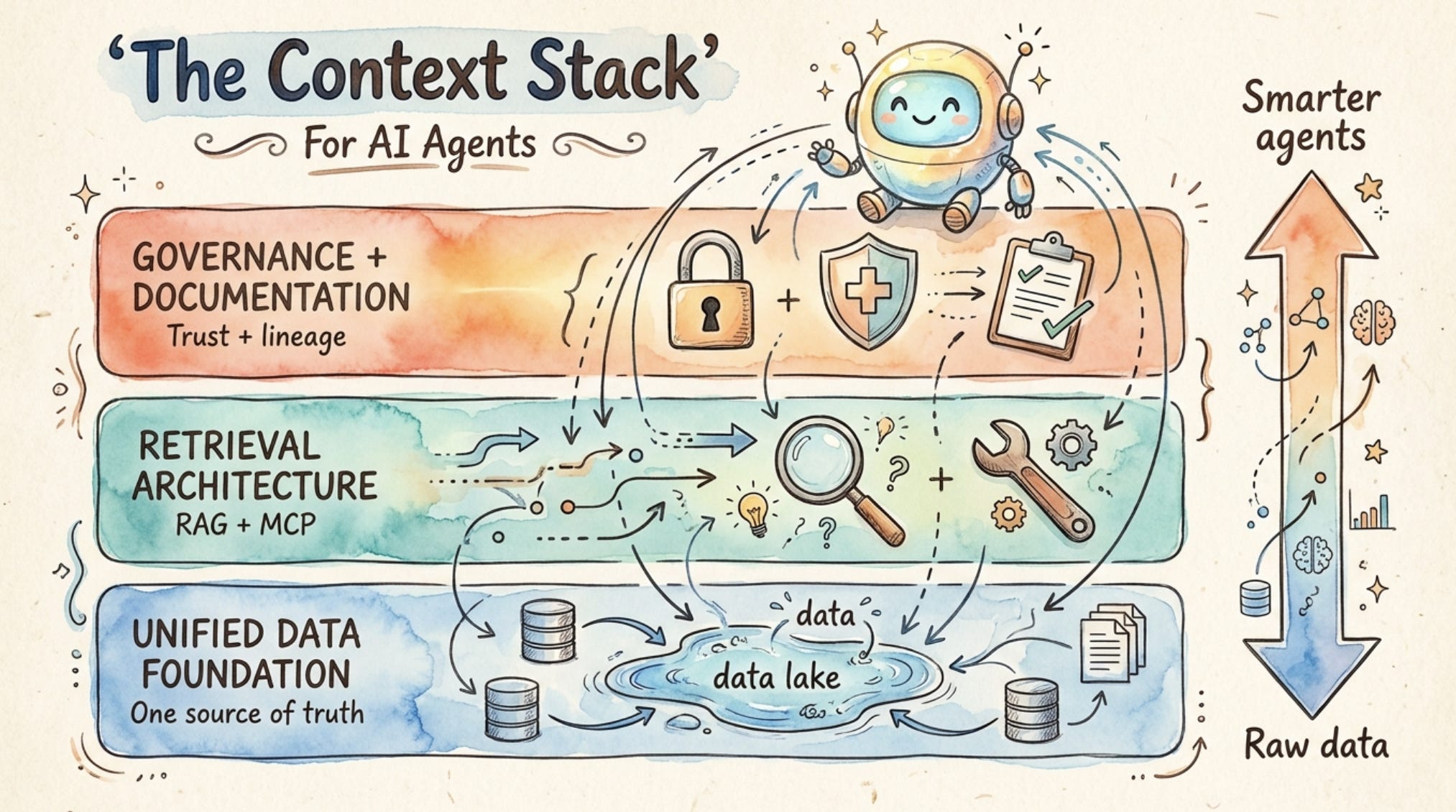
The framework: the three-layer context stack
Here is how I think about preparing an organization for agents. There are three layers that must all be healthy before agents can deliver value. I call it the Context Stack.
Get all three right, and your agents become smarter as your organization grows. Get any one wrong, and you’re building a performance ceiling you’ll hit faster than you expect.
The three layers are:
Unified data foundation: One governed, trusted source of truth for enterprise data
Retrieval architecture: How agents find and pull the right information at the right time
Governance and documentation: Who authorized what access, and why
Let’s go through each one.
Layer 1: Unified data foundation
The first thing agents need is a single, trusted place to find information.
Not 14 databases, 3 SharePoint sites, and a folder on someone’s laptop that hasn’t been touched since 2023.
Fragmented data leads to fragmented answers. When agents synthesize information from multiple ungoverned sources, inconsistencies compound. One source says the refund window is 30 days. Another says 14. The agent picks one. It is wrong half the time. And now your agent is undermining trust with customers.
The architectural answer is a unified data platform. In the Microsoft ecosystem, this is Microsoft Fabric OneLake. Business units create governed data products that live in domain-specific workspaces. Those data products become the canonical input for any AI workload. The agent doesn’t touch raw systems. It touches certified data products.
This is not a new idea. Data mesh and data product thinking have been in the enterprise lexicon for years.
