
Why tokenomics decides which AI agents survive production
Intelligence is the easy part now. Intelligence at sustainable unit cost is the moat.

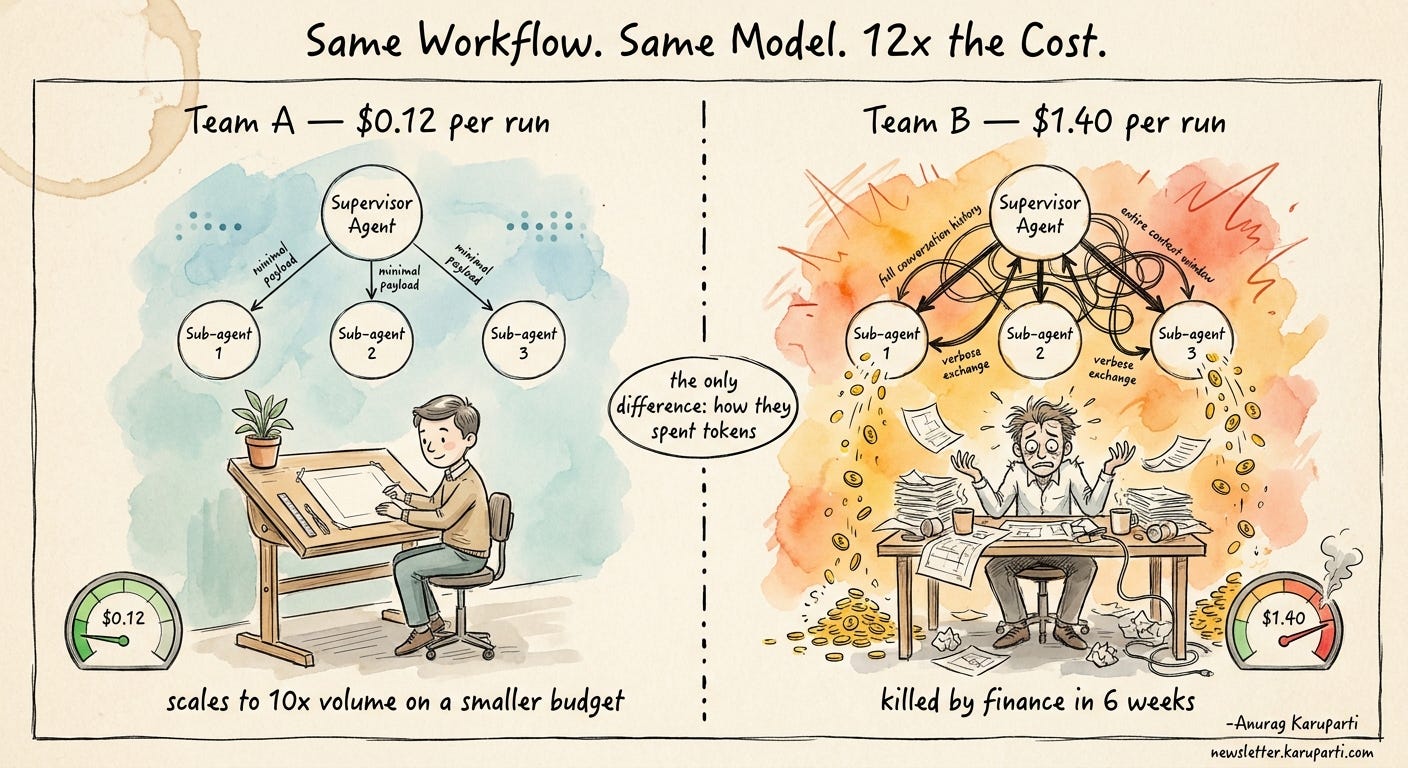
Two teams deployed the same multi-agent workflow last quarter. One costs $0.12 per run. The other costs $1.40. Same model. Same outcome. The only thing that changed was how they spent tokens.
The team running at $1.40 had a working POC, a happy demo, and a board deck full of green checkmarks. Six weeks into production, finance pulled the plug.
The team running at $0.12 is now serving ten times the volume on a smaller infrastructure budget than the original POC.
This is the part of the agentic AI conversation that almost nobody is having out loud.
We talk about model quality, evals, context engineering, orchestration patterns.
We do not talk about the unit economics of a single agent run, even though that number is the only thing that decides whether the system gets to live past the pilot.
Tokenomics is not an optimization concern you handle later. It is the architecture constraint that decides whether your project ever ships, scales, or survives the first real CFO review.
This week’s edition is about why.

First, what is tokenomics in AI?
Tokenomics in AI is the cost structure of running large language models, where every interaction is priced by the unit of work the model actually does: tokens.
A token is roughly three quarters of a word, and every prompt you send, every document you stuff into context, every tool output the model reads, and every word it generates back is metered and billed.
In a traditional software system, your unit cost is roughly fixed. A request hits an API, runs some logic, returns a response. Compute is cheap and predictable.
In an AI system driven by LLMs, your unit cost is variable, and it scales with how much the model has to read and write to do its job.
That single shift is what makes AI economics behave more like a utility bill than a software license.
The numbers are no longer abstract. Google now processes around 1.3 quadrillion tokens a month, a 130-fold jump in just over a year.
Deloitte’s 2026 CFO guidance flags AI as the single fastest-growing line item in enterprise technology budgets, eating a quarter to a half of IT spend at the firms leaning in hardest.
Unit token prices are falling, but total enterprise spend is climbing because volume is climbing faster than price is dropping.
Tokenomics is the discipline of designing systems so that this curve works in your favor instead of against you. It covers four cost surfaces:
Prompt tokens. Everything you send into the model: instructions, system prompts, user input, retrieved documents, tool outputs. A two-thousand-token system prompt prepended to every call is a tax you pay on every interaction for the life of the system.
Context tokens. The conversation history, scratchpad, and accumulated state the model carries between turns. In agent systems this grows fast.
Reasoning tokens. A newer line item. Models with extended chain-of-thought consume tokens for the thinking they do internally, often invisible to the user but very visible on your invoice.
Output tokens. What the model writes back. Usually the smallest bucket. Almost always the easiest to control.
In a chatbot, these four buckets are predictable. In an agentic system, they multiply, and that is where most enterprise AI projects quietly bleed out.
The token multiplier problem in agentic AI
Most teams learn tokenomics the hard way. They build a chatbot, see a clean cost-per-call, and assume agentic systems will scale the same way. They will not.
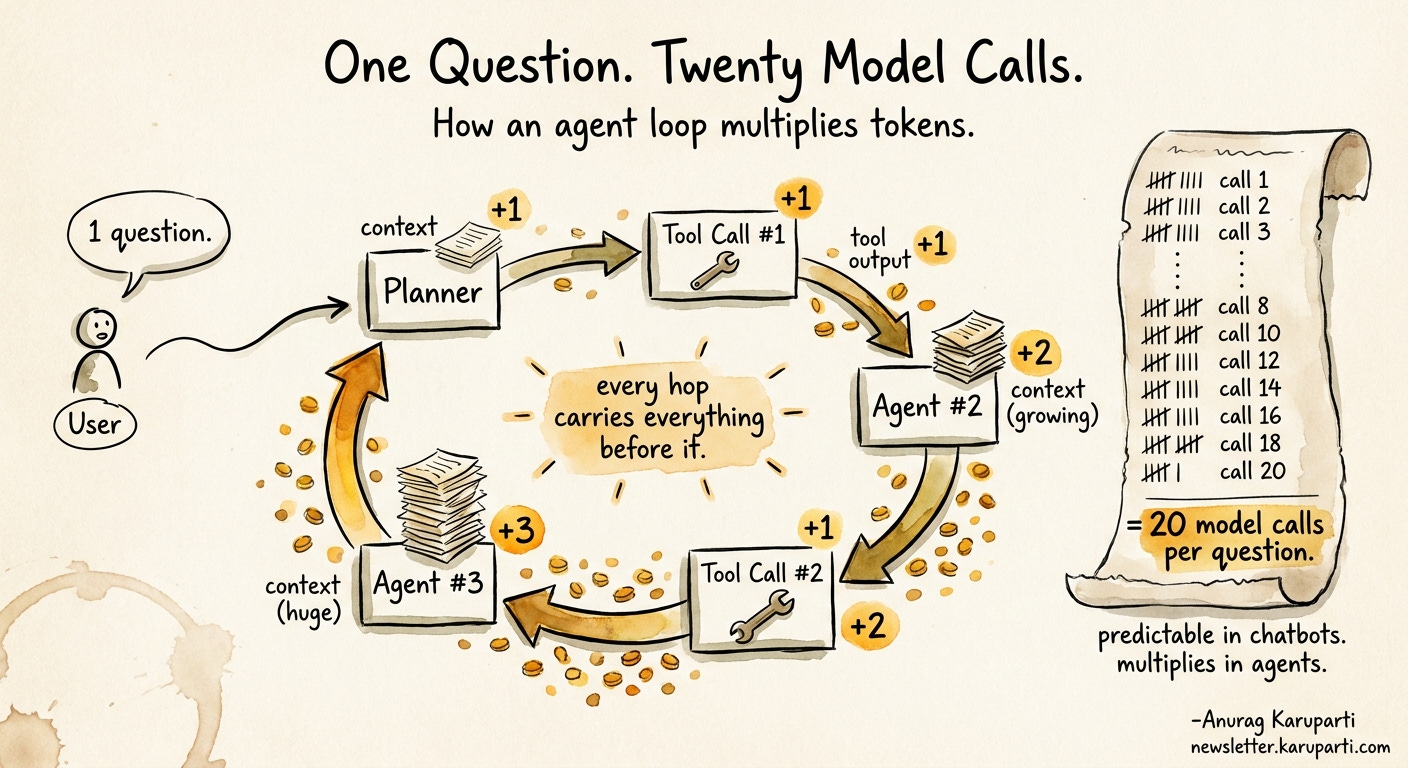
A single LLM call has three token buckets: the input prompt, the context you stuff in, and the output you get back. Predictable, easy to model, easy to budget.
An agent run is a different animal. Every hop multiplies tokens. The planner reads context, decides on a tool, calls the tool, reads the tool output, passes it to the next agent, which reads its own context, decides on its own tool, and on it goes. By the time a five-step agent loop finishes, you have not made one model call. You have made eight, twelve, sometimes twenty, each one carrying the accumulated context of every step before it.
Run the math on a real workload. Ten thousand users, five thousand tokens per agent run on a naive design, twenty thousand on a heavy one. At enterprise volume, the difference between a thoughtful architecture and a lazy one is not a percentage. It is an order of magnitude.
The painful part is that almost every team discovers this after the POC ships. The pilot ran on a hundred internal users. The cost looked fine. Then marketing turned it on for the customer base, and the bill went from a rounding error to a line item the CFO wants explained in a meeting you did not want to be in.
Tokenomics is the gravity of agentic AI. You can ignore it for a while. You cannot escape it.
The three architecture decisions tokenomics forces
Once you accept that token cost compounds with every agent hop, the architecture decisions stop being style choices. They become survival choices. There are three that matter most.
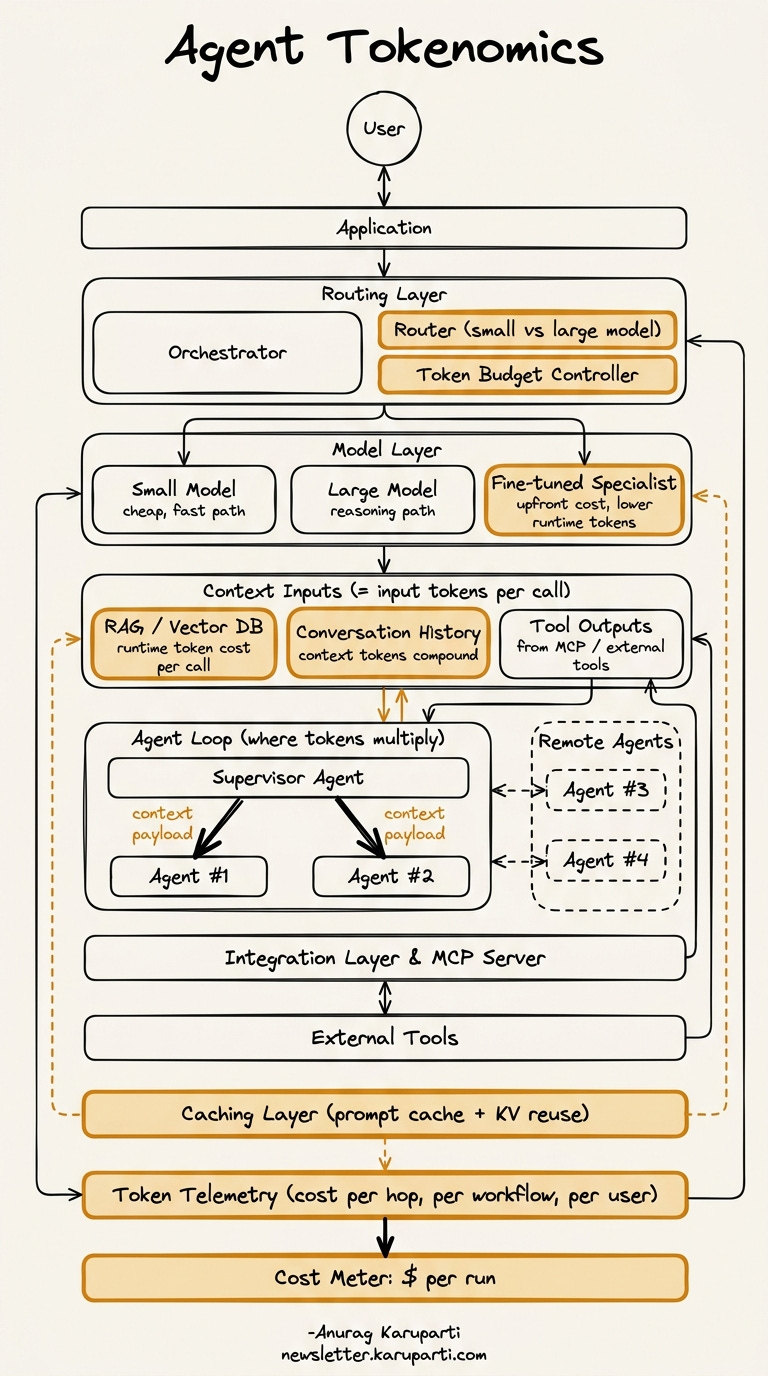
The diagram above is the map. Every amber box is a place where token cost is either gets compounded or controlled.
Cost gets decided at the top, in the routing layer (small model vs. large model) and the token budget controller.
Cost gets compounded in the middle, inside context inputs (RAG, conversation history, tool outputs) and the agent loop, where every supervisor-to-sub-agent handoff carries a context payload that the next agent has to re-read and pay for.
Cost gets controlled at the bottom, by the caching layer, the token telemetry, and the cost meter that turns all of this into a dollar figure per run.
The survival question is simple: how much of the amber in your architecture is working for you (caching, routing, telemetry, budgets) and how much is working against you (uncapped context growth, full-history handoffs, no per-hop budgets)?
The next three sections walk through the three decisions that decide how much amber is working for you and how much is working against you.
Decision 1: RAG vs. fine-tuning
The naive read is that fine-tuning is expensive and RAG is cheap. The honest read is that you are choosing where to pay.
Fine-tuning is a large upfront cost and a smaller runtime cost. The model already knows the patterns, so your prompts get shorter and your context gets thinner. Good for narrow, repeatable workflows where the domain is stable.
RAG is a small upfront cost and a larger runtime cost. Every query pulls fresh chunks into context, which means every query pays for those tokens, every time. Good for workflows where the underlying knowledge changes faster than you can retrain.
Example. A support agent at a SaaS company answers the same fifty intent categories ten thousand times a day. The team started on RAG, retrieving twelve chunks averaging four thousand tokens per query. Cost per call: roughly $0.018. They fine-tuned a small model on six months of resolved tickets, dropped retrieval to two chunks for edge cases only, and landed at roughly $0.004 per call. Same quality bar, four times cheaper, at a volume where the upfront training cost paid back in eleven days.
The opposite call: a legal research agent where case law updates weekly. Fine-tuning would be obsolete the day it shipped. RAG is the right answer there, and the right move is to invest in retrieval quality so each query pulls four precise chunks instead of twelve mediocre ones.
The teams that survive production pick deliberately. The teams that do not survive default to RAG because it feels cheaper, then watch their token bill grow linearly with usage forever.
Decision 2: model routing
The temptation is to use the biggest model for everything. It is the easiest decision to defend in a design review and the hardest to defend in a budget review.
The teams that scale route aggressively. Small model with a tight, well-engineered prompt for the eighty percent of calls that are simple.
Large model only for the twenty percent that actually need the reasoning.
A small model with a good context beats a large model with a lazy prompt almost every time, on cost and latency, and often on quality.
Example. A document processing agent had four steps: classify the document, extract key fields, validate against business rules, and draft a summary. The first version ran every step on a frontier model. Cost per document: $0.42. The team profiled each step against an eval set, then re-routed: a small model for classification (a one-token decision), a small model for extraction (structured output, no reasoning needed), the frontier model only for validation (where edge cases actually require reasoning), and a mid-tier model for summarization. New cost per document: $0.06. Quality on the eval set was within one point of the all-frontier baseline. Same workflow, seven times cheaper, because three out of four hops never needed the expensive model in the first place.
The architectural question is not “which model is best.” It is “what is the cheapest model that meets the bar for this specific step.” Ask that question once per agent hop and your token bill drops by half before you have changed a single line of business logic.
Decision 3: agent orchestration
This is the decision most teams underweight, and it is the one with the largest token impact.
Every handoff between agents carries context. If you pass the full conversation history to every sub-agent, you are paying for the same tokens repeatedly, at every hop, on every run.
If you summarize aggressively between hops, you cut token cost dramatically but risk losing the nuance the next agent needs. If you let agents call each other in unbounded loops, you have built a token incinerator.
Winning teams design handoffs the way distributed systems engineers design network calls. Minimum payload, maximum signal, hard limits on retries and depth. They treat context as a scarce resource the orchestrator allocates, not a free variable each agent helps itself to.
Example. A research agent had a supervisor coordinating three sub-agents: a web searcher, a document reader, and a synthesizer. The first version passed the full conversation history to every sub-agent on every hop. By the third research loop, each sub-agent call was carrying eighteen thousand tokens of context, ninety percent of which was irrelevant to the task that sub-agent was doing. Cost per research session: $1.40. The team rewrote the orchestrator to pass each sub-agent only the structured slice it needed (the searcher got the query and prior search results, the reader got the document IDs and the extraction schema, the synthesizer got the structured outputs from the other two). Average payload per hop dropped to twenty-two hundred tokens. Cost per session: $0.12. Same agents, same model, same final answer. The win was entirely in what the orchestrator chose not to pass.
Most production failures I have seen are not model failures. They are orchestration failures dressed up as cost overruns.
The optimization playbook winning teams use
Architecture sets the ceiling. The playbook below is how the teams that scale stay under it.
Input reduction. Strip the prompt to what the model actually needs to make the next decision. Most production prompts carry two or three paragraphs of instructions the model learned to ignore six versions ago. Cut them. Measure quality. Cut more.
Context control. Do not let the agent decide how much history to carry. The orchestrator decides. Use sliding windows, structured summaries, and explicit context budgets per hop. If a sub-agent does not need the full transcript, it does not get the full transcript.
Output limits. Set max tokens on every call. Long outputs are where unbounded cost lives. If the answer should be a JSON object with four fields, cap the output at the size of that object. The model will comply.
Caching. Cache the parts of your prompt that do not change. System instructions, tool schemas, retrieved documents that get reused. Prompt caching alone has cut token spend by thirty percents with zero quality impact and minimal engineering effort. If you are not using it yet, this is the highest-leverage change you can make this week.
Routing telemetry. Log token cost per agent hop, per workflow, per user segment. You cannot optimize what you cannot see, and the teams that survive are the teams who treat token spend as a first-class observability metric, not an end-of-month surprise on the cloud bill.
None of these are exotic. All of them are boring. That is the point. Tokenomics discipline is boring infrastructure work, and boring infrastructure work is what separates the systems that scale from the demos that did not.
The survival frame
Here is the part nobody wants to put on a slide.
Every enterprise AI team is going to hit the tokenomics wall. The question is whether they hit it in design review, in staging, or in production with a CFO on the call.
The teams that designed for it from day one will scale. Their unit economics get better as volume grows because their architecture compounds in their favor. The teams that did not will spend the next two years explaining to leadership why the POC that cost fifty dollars a day now costs five thousand dollars a day, and why the obvious fix requires rewriting the orchestration layer they shipped last quarter.
The agentic AI projects that survive production will not be the ones with the smartest agents. They will be the ones with the cheapest, most predictable, most controllable token spend. Intelligence is the easy part now. Intelligence at sustainable unit cost is the moat.
Tokens are your compute budget. Context is your leverage. Prompts are your control plane.
Build like you believe that, or build something the business will quietly turn off in six months.
That is the choice tokenomics is forcing on every team this year. The ones who took it seriously in the design phase are already pulling ahead. The ones who did not are about to find out why.
♻️ If this was useful, share it with someone building with AI.
✉️ Subscribe at newsletter.karuparti.com so you never miss an edition.
P.S. Want more? 👋
1/ My visual guide to agentic AI → Gumroad
2/ Deep dives on agentic AI architecture → LinkedIn
3/ Real-time takes on breaking AI news → X
4/ Casual hot takes and community → Threads
5/ Visual frameworks and carousels → Instagram
6/ 60-second production lessons → TikTok
7/ The full newsletter, free → newsletter.karuparti.com
Read this