
Loop engineering for the enterprise: close the loop or fall behind
Loop engineering is the difference between an agent capable of self-evolution and one that goes extinct. Here are the six architectural layers that close the loop.

Most AI systems process a request and stop. The ones that win never stop. They close the loop.
There is a term spreading through the agent-building community right now: loop engineering. The internet is buzzing about it, and like most things that go viral fast. So, I spent the last two weeks pulling it apart to figure out what is real, what is hype, and what actually matters for teams shipping agents into production.
Here is what I found. Loop engineering is not a new model. It is not a framework you install. It is a way of thinking about the architecture of long-running, self-improving systems.
The term was popularized by popularized by top engineering leaders like Boris Cherny (Head of Claude Code), Addy Osmani (Google’s Engineering Leader) and Peter Steinbeger (Creator of OpenClaw)
This week’s edition is about that difference, and the six engineering layers that make it possible.
The enterprise pain points
Imagine you are the platform lead at a mid-sized insurance company. Your team has built a claims-triage agent that reads incoming claims, classifies them, pulls the relevant policy, and drafts a recommendation for a human adjuster.
It works. On launch day it handles 60% of routine claims without escalation, and leadership is thrilled.
Then it stops getting better. Six weeks later it is still at 60%. The same edge cases fail the same way. The agent misreads the same ambiguous policy clauses on Monday that it misread the previous Monday. Adjusters start double-checking everything, which erases most of the time savings.
The diagnosis is simple. They built an open-loop system. A request comes in, the agent processes it, an answer comes out, and that is the end of the line. Nothing flows back. The agent has no way to notice it was wrong, no way to learn from the adjuster’s correction, no memory of last week’s mistake. It is a very expensive function call.
Your team built an agent. But what is needed is a loop.
The framework: open loop versus closed loop
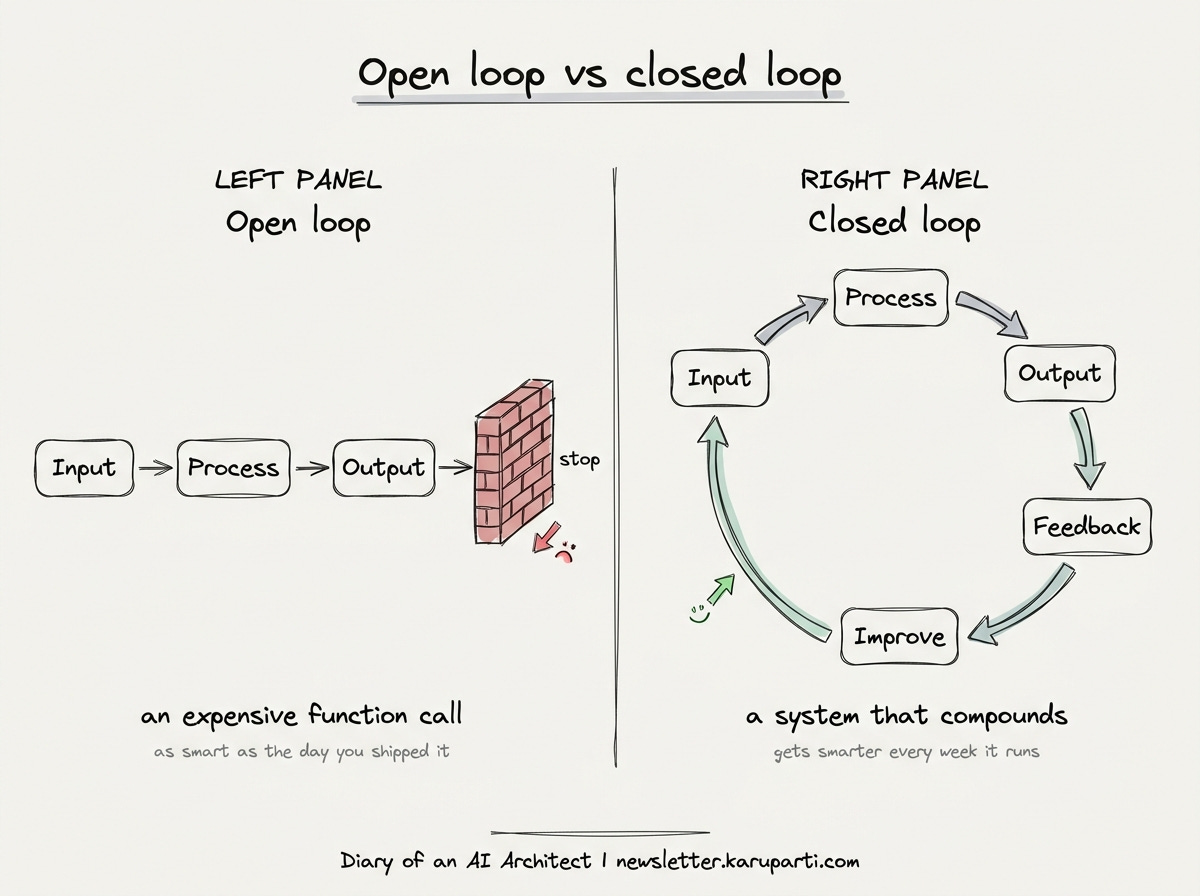
Most AI systems today look like this:
Input → Process → Output → (stop)
A self-improving system looks like this:
Input → Process → Output → Feedback → Improve → back to Input
That second arrow, the one that bends back to the beginning, is the entire game. It is the difference between a system that is as smart as the day you shipped it and a system that compounds.
But that loop is not magic, and this is where most of the loop engineering hype falls apart. People talk about self-improving agents like you sprinkle a feedback step on top and intelligence emerges. It does not work that way.
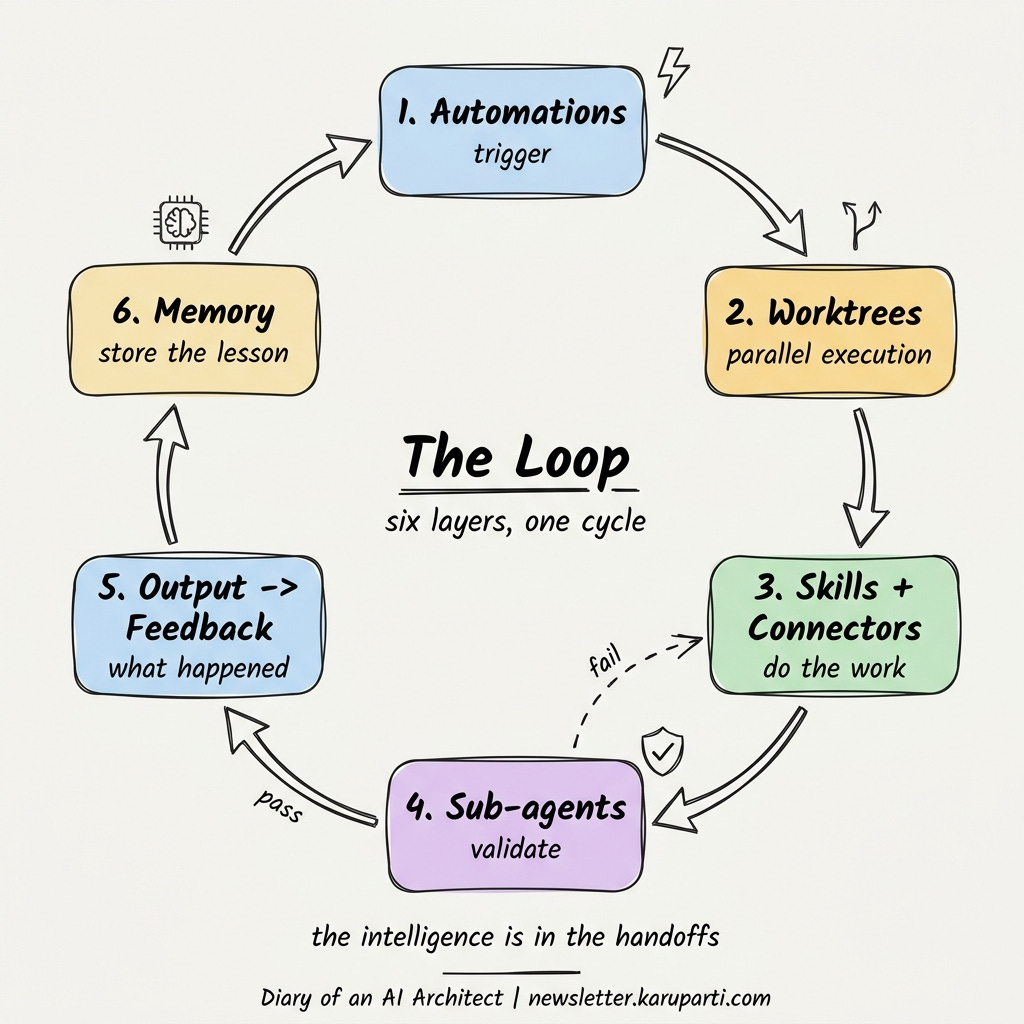
The loop is held together by six engineering layers. Each one is a real architectural decision with real trade-offs. Get all six working together and the loop closes.
The six layers are:
Automations: the trigger layer
Worktrees: the parallel execution layer
Skills: the procedural memory layer
Connectors: the real-world links layer
Sub-agents: the validation layer
Memory: the state layer
Let’s go through each one.
Layer 1: Automations, the trigger layer
The first thing a self-improving system needs is a way to start without you.
Automations initiate workflows based on time, events, or system conditions. An email arrives. A database row updates. A calendar event fires. A claim lands in the queue. The trigger launches the full pipeline so execution is structured, not ad hoc.
This is the layer that moves an agent from “I asked it” to “it noticed and started on its own.” That shift sounds small. It is not. An agent you have to invoke is a tool. An agent that responds to the world is a system.
The architectural caution: triggers are where runaway loops are born. An event-driven agent that triggers another event can cascade. Before you wire automations, define the kill switch and the rate limit. A loop that starts itself must also be a loop you can stop.
Layer 2: Worktrees, the parallel execution layer
Once work starts itself, you hit the next wall: throughput. One agent processing one task at a time does not scale to enterprise volume.
Worktrees are the answer. The name borrows from the git concept that coding agents use, where multiple branches exist side by side without stepping on each other. Applied to agents, it means multiple agents execute independently across isolated branches.
Three properties matter here:
Task isolation: branches don’t interfere with each other, so one agent’s work can’t corrupt another’s.
Concurrent processing: speed improves without collision risk.
Independent state: each branch carries its own context.
The mistake I see teams make is scaling vertically first, throwing a bigger model at a serial pipeline, when the real constraint is concurrency. Worktrees solve the concurrency problem at the architecture layer, not the model layer.
Layer 3: Skills, the procedural memory layer
Here is where the loop starts to feel intelligent.
Skills are reusable units of logic that encapsulate repeatable instructions an agent applies across tasks. Think of them as procedural memory, the “how to do this” that an agent does not have to rediscover every time.
A skill is:
Step-by-step: an execution pattern that improves reasoning across workflows.
Modular: plug-and-play, so agents adapt faster.
Reusable: written once, applied everywhere it fits.
Picture a skill pool: code understanding, data analysis, web search, summarization, database queries. The agent core combines the right skills for the task in front of it. A triage claim needs policy lookup plus summarization. An appeal needs document comparison plus precedent search. Same skill pool, different combinations, higher-quality output with less effort.
This connects directly to something I wrote about in my edition on context engineering. Skills are how you stop stuffing every instruction into the prompt and instead give the agent a library of capabilities it composes on demand. The prompt gets shorter. The behavior gets more reliable. The system gets cheaper to maintain.
Layer 4: Connectors, the real-world links layer
An agent reasoning in isolation is a chatbot. An agent that touches real systems is infrastructure.
Connectors are the links to the outside world:
APIs: REST, GraphQL, custom endpoints for external data and actions.
Data and databases: SQL, NoSQL, cloud storage for persistence.
Tools and protocols: MCP servers, CLI commands, web search, enterprise systems.
This is the layer where the agent stops reasoning about the world and starts acting on it. “What does the policy say?” is a retrieval question. “Flag this claim for fraud review and notify the adjuster” is a write action. Both require connectors, and the second one requires you to take security seriously.
Every connector is an attack surface and a blast radius. The discipline that matters here is least privilege and identity. An agent should act with the narrowest permissions that let it finish the job, every call should be authenticated, and every action should be auditable.
The Model Context Protocol has become the common standard for wiring tools into agents precisely because it bakes identity and policy into the connection rather than bolting it on later.
Layer 5: Sub-agents, the validation layer
This is the layer that separates teams who ship reliable agents from teams who ship confident hallucinations.
The pattern is simple: separate the builder from the judge.
Generator: creates the initial output.
Validator: reviews, checks, and verifies it against the rules.
Approval gate: only validated output moves forward.
Feedback loop: flagged issues route back for another pass.
One agent generates the claim recommendation. A separate agent, with a different prompt and a different job, checks it against policy constraints, regulatory rules, and the known failure cases. If it passes, it ships. If it fails, it goes back with the specific reason.
Why two agents instead of one that checks its own work? Because a model grading its own output has the same blind spots that produced the error. Multiple eyes, even when they are both models, catch more. Continuous validation is what turns a 60% agent into a 90% agent without touching the underlying model.
This is the operational arm of something I argued a few editions ago: your evals are your moat. The validator sub-agent is where your eval logic lives at runtime. The ground truth your business wrote down becomes the rubric the validator enforces on every single output, not just in a test suite but in production.
Layer 6: Memory, the state layer
The final layer is the one that makes the loop a loop instead of a circle that returns to zero.
Memory preserves state across passes:
Context storage: past interactions persist across conversations and runs.
Retrieval: relevant history is fetched to inform the current decision.
Learning loop: system intelligence updates based on outcomes.
Without memory, every pass starts fresh and the agent makes the same mistake forever.
This is where intelligence actually emerges, and it is worth being precise about how. The loop does not make the model smarter. The model weights do not change. What changes is the context the system carries into each pass. Memory is the substrate that lets feedback from layer five accumulate instead of evaporate.
The loop never breaks, and that is exactly the point. Each pass through makes the next one smarter, because each pass leaves something behind for the next one to use.
How the six layers form the loop
Put the six layers on the loop and you can see how they hand off to each other. Automations start it. Worktrees parallelize it. Skills and connectors do the work. Sub-agents validate it. Memory carries the lesson forward to the next pass.
Notice that no single layer is the magic. The intelligence is in the handoffs. A trigger with no memory is automation. Memory with no validation is a system that confidently remembers wrong answers. Validation with no connectors is an agent grading work it never actually did. The loop only compounds when all six layers are present and wired in sequence.
What does it mean for the enterprise and risks?
When I review an agent architecture now, I do not start by asking which model they chose. I ask one question first: where does the loop close?
If the answer is “it doesn’t,” I know exactly why the system plateaued, and I know none of the prompt tuning they are about to attempt will fix it. You cannot prompt your way out of a missing feedback layer.
For most teams, the fix is not a better model. It is three of the six layers they had skipped. They add a connector to read the adjuster’s accept-or-override signal, a validator sub-agent that enforces policy constraints before drafting, and a memory layer that stores every override as a new case. Within a month the agent moved off its plateau, because for the first time it could learn from the humans correcting it.
Evals are fundamental to closing the loop. I recently published a thought piece outlining a three step evaluation framework: establish a strong ground truth foundation, apply a judgment layer to assess performance, and create a continuous feedback loop that drives ongoing improvement. Link
The teams that win the next two years are not the ones with the best model. Everyone has the same models. The winners are the ones who engineer the loop, because a closed loop compounds and an open loop decays.
One risk I see as loops improve and become increasingly autonomous is that humans grow unaware of the underlying mechanics. As the human in the loop gets eliminated entirely, we accumulate comprehension debt: a growing gap between what the system does and what we actually understand about how it does it. This leads to cognitive surrender, where we trust these systems so completely that we stop understanding what's happening at all.
As Addy Osmani lays out in his blog, it's essential to stay the engineer even as the loops improve, to keep a working understanding of the system rather than ceding it entirely.

The bottom line
Most AI systems process a request and stop. Long running self-improving systems close the loop, and that loop is held together by six engineering layers: automations to trigger, worktrees to parallelize, skills and connectors to act, sub-agents to validate, and memory to carry the lesson forward.
Before you reach for a bigger model, find where your loop fails to close. The gap is almost always a missing layer, not a weak model. Close the loop, and your agent stops being an expensive function call and starts becoming a system that gets smarter every week it runs.
♻️ If this was useful, share it with someone building with AI.
✉️ Subscribe at newsletter.karuparti.com so you never miss an edition.
P.S. Want more? 👋
1/ My visual guide to agentic AI → Gumroad
2/ Deep dives on agentic AI architecture → LinkedIn
3/ Real-time takes on breaking AI news → X
4/ Casual hot takes and community → Threads
5/ Visual frameworks and carousels → Instagram
6/ 60-second production lessons → TikTok
7/ The full newsletter, free → newsletter.karuparti.com
References
Credits to Addy Osmani for this insightful blog: Link