
12 proven strategies to reduce AI costs at scale
How leading teams optimize AI economics while maintaining quality, reliability, and business impact.
Last month a friend pinged me at 11pm. One line: “Our AI bill just hit $40k. Help.”
His team shipped a great feature.
Users loved it.
Then the invoice landed.
Same model. Same product. The cost had quietly tripled in six weeks.
Nobody did anything wrong. Nobody did anything on purpose either. That was the problem.
Here is what I told him. And here is what I tell every team that hits this wall.
You do not have a model problem. You have a habits problem.
LLM cost is not one big leak. It is twelve small ones.
Let me walk you through all twelve.
First, why this matters now
Token prices keep falling.
Yet enterprise AI bills keep climbing.
How? Because volume grows faster than price drops.
Google now processes over a quadrillion tokens a month. Deloitte’s 2026 CFO guidance calls AI the fastest-growing line item in tech budgets.
Translation: your bill is going up, even when the price per token goes down.
The teams that survive are not the ones with the cheapest model. They are the ones with the cleanest habits.
So let us fix the habits.

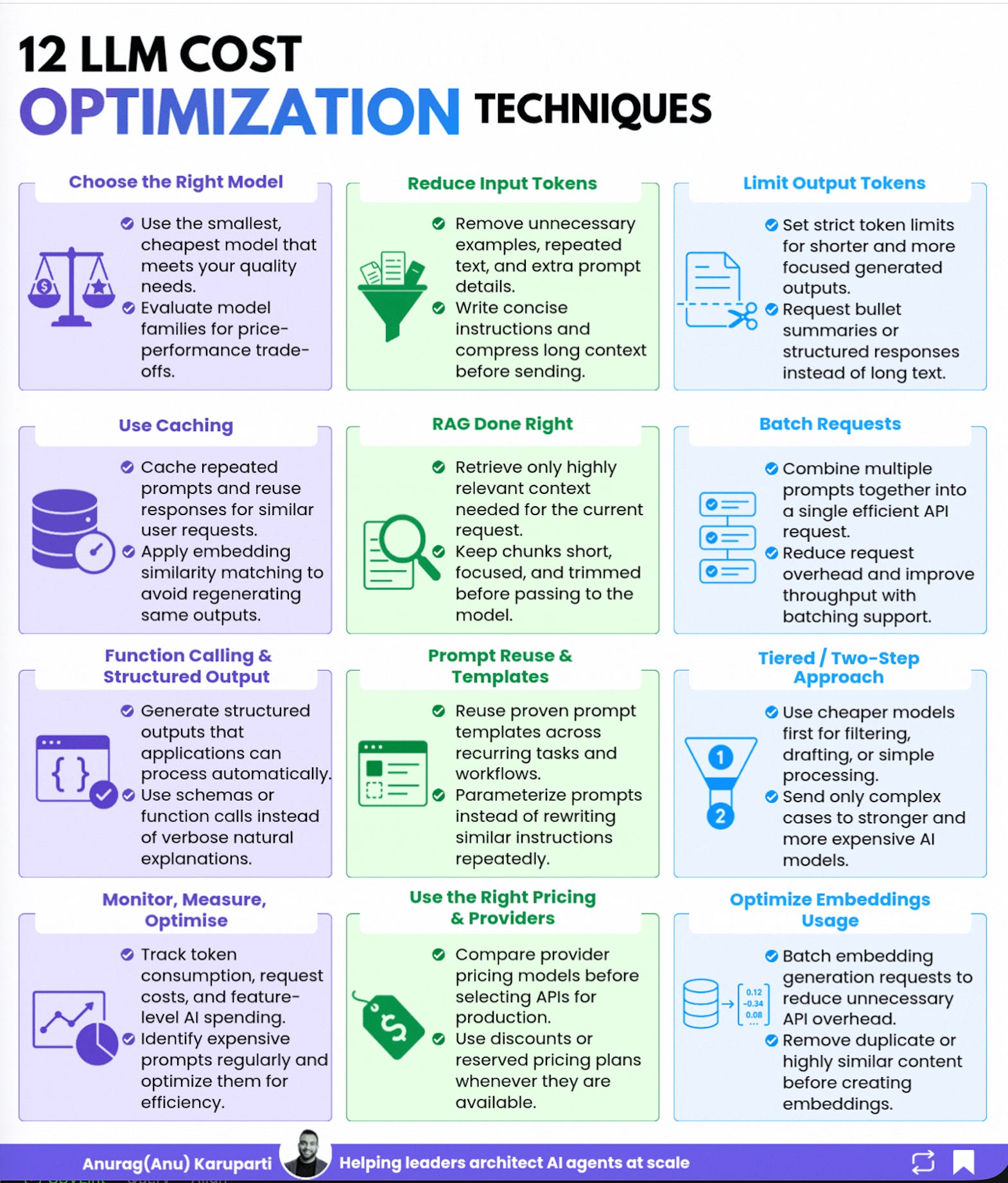
1. Choose the right model
Most teams reach for the biggest model by default.
Big mistake.
The biggest model is rarely the right one. It is just the safest-feeling one.
Pick the smallest, cheapest model that still clears your quality bar.
A simple rule I use:
- Routing, classifying, extracting? Small model. (GPT-5.4-mini, Claude Haiku 4.5)
- Drafting, summarizing? Mid model. (GPT-5.4, Claude Sonnet 4.6)
- Hard reasoning, final answers? Large model. (GPT-5.5, Claude Opus 4.8)
Most workloads are small-model work wearing a large-model price tag.
2. Reduce input tokens
You pay for every word you send. Not just the words you get back.
So stop sending junk.
Cut the repeated examples. Cut the stale instructions. Cut the giant block of context you pasted “just in case.”
A 2,000-token system prompt on every call is a tax. You pay it forever.
Write tight. Send less. The model does not need your life story.
3. Limit output tokens
Long answers feel impressive. They are also expensive.
Set a hard cap on output length.
Ask for bullet points. Ask for structured responses. Ask for “answer in 3 sentences.”
You will be shocked how often a 50-token answer beats a 500-token one. For the user and the bill.
4. Use caching
Your users ask the same things over and over.
So stop re-generating the same answers.
Cache repeated prompts and responses. Use embedding similarity to catch the near-duplicates too.
Many providers now offer prompt caching for the static part of your prompt. That alone can cut input cost on long system prompts by half or more.
Free money. Take it.
5. RAG done right
Bad RAG is a silent budget killer.
People dump huge chunks into context and hope the model sorts it out.
The model does sort it out. And it charges you for every token while it does.
Retrieve only what the current question needs. Keep chunks small. Trim before you send.
Good RAG is not “more context.” It is less, but exactly right.
6. Batch requests
One-by-one API calls add up. Each one carries overhead.
If you are processing many items, batch them.
Group prompts into a single efficient call where the task allows it. Many providers also offer a batch tier at a steep discount for non-urgent jobs.
Overnight work does not need real-time pricing.
7. Function calling and structured output
Free-text answers are hard for code to use. So you ask the model to “explain,” then you parse the mess.
That explanation costs tokens. The re-asks cost more.
Use function calling and structured output instead.
Ask for clean JSON. Define a schema. Skip the verbose natural-language wrapper.
Fewer tokens. Fewer retries. Less glue code.
8. Prompt reuse and templates
Every team rewrites the same prompt five slightly different ways.
Each version drifts. Each one gets a little longer. Nobody owns it.
Build a library of proven, parameterized templates instead.
Write the prompt once. Tune it once. Reuse it everywhere.
This is not just a cost win. It is a quality win and a sanity win.
9. Tiered, two-step approach
Not every request deserves your most expensive model.
So filter first.
Use a cheap model for triage: sort, draft, simplify. Send only the hard cases up to the expensive model.
Think of it like a hospital. A nurse sees everyone. The surgeon sees the few who actually need surgery.
Most of your traffic never needs the surgeon.
10. Monitor, measure, optimize
You cannot fix what you cannot see.
Most teams have no idea which feature burns the most tokens. So they guess. And they guess wrong.
Track token spend by feature, by user, by request type.
Find the top three offenders. Fix those first.
A dashboard you check weekly beats a heroic cleanup after the bill explodes.
11. Use the right pricing and providers
Provider pricing is not flat. It changes by model, by region, by commitment.
Most teams pick a provider once and never look again.
Compare before you commit to production volume.
Look at reserved capacity. Look at committed-use discounts. Look at whether a different provider serves your specific workload cheaper.
This is a procurement decision, not just an engineering one. Treat it like one.
12. Optimize embeddings usage
Embeddings feel cheap. At scale, they are not.
Teams re-embed the same content over and over. They embed near-duplicates. They batch nothing.
Fix three things:
Batch your embedding requests.
Skip duplicate and near-identical content.
Cache embeddings you already have.
Small per-call cost. Massive total cost. Worth the cleanup.
The pattern under all twelve
Read the list again. Notice something?
None of these are clever.
There is no secret model. No magic flag. No vendor trick.
Every single one is the same move: send fewer tokens, and only the ones that matter.
That is the whole game.
LLM cost optimization is not a one-time project. It is a discipline you bake into how your team builds.

How this maps to Azure
If you are building on Azure, you do not have to wire all twelve by hand. Most of them have a home in the platform.
Here is how I map them:
Choose the right model + tiered routing: Use Microsoft Foundry model catalog to deploy a mix of small and large models, and route between them. Cheap model first, expensive model only when needed.
Caching + reduce input tokens: Put Azure API Management in front of your models as an AI gateway. It supports semantic caching, token limits, and token metrics out of the box.
RAG done right: Use Azure AI Search with tight chunking and hybrid retrieval, so you send the model less context, not more.
Monitor, measure, optimize: Use Azure Monitor and the token metrics from API Management to see spend by feature and catch spikes before finance does.
Embeddings: Cache embeddings in Azure Cosmos DB or your vector store, and batch generation jobs instead of embedding one item at a time.
Here is the shape of it:
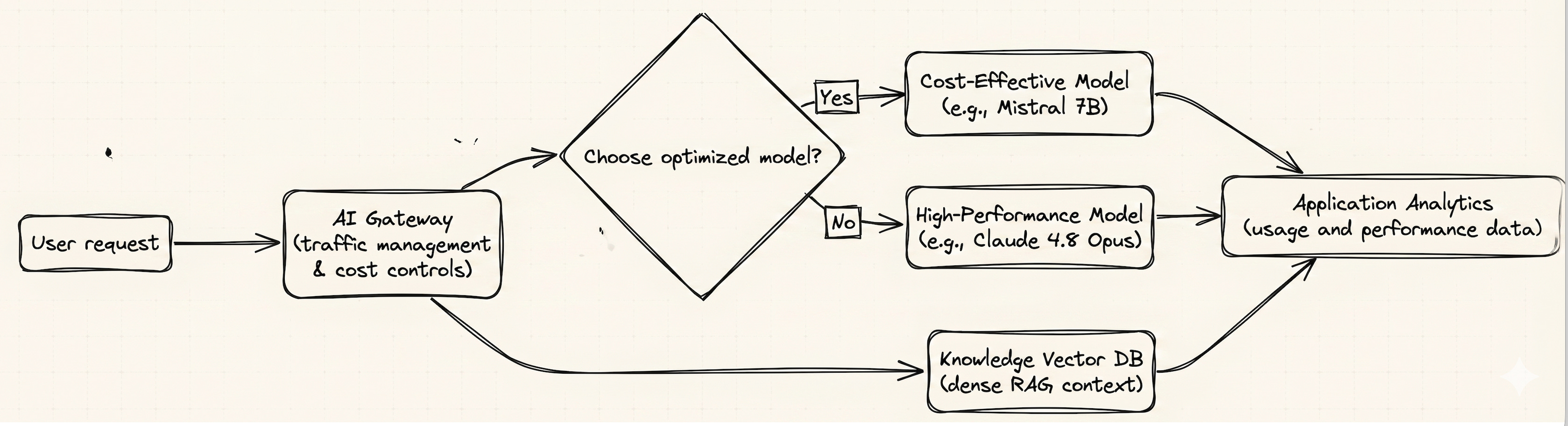
The gateway is the key piece. It is where caching, token limits, and measurement all live in one spot. Most of your savings flow through that single layer.
Microsoft Learn references:
The bottom line
Your LLM bill is not one big leak. It is twelve small ones, and most teams never plug any of them until the CFO asks why the number tripled.
Start with three this week: pick the right model, cap your output, and turn on caching. Those three alone usually cut the bill by a third.
Then build the habit. Cheap tokens are not an accident. They are a design choice you make on every call.
♻️ If you found this valuable, share it with your network. ✉️ Subscribe for more: newsletter.karuparti.com
Disclaimer: The stories and scenarios in this article are hypothetical, inspired by patterns observed across similar real-world experiences. They are used to convey key concepts more effectively and do not represent any specific individual or organization.